
在本演示中我将介绍Turbo Intruder插件的基本功能及相关的demo测试。Turbo Intruder是一个从头开始构建的并充分考虑其执行速度的研究级开源Burp Suite扩展。此外我还讨论了有关基础HTTP滥用的例子在启用Turbo Intruder后其速度得到了显著的提升。因此你也可以在任何你编写的工具中获得类似的速度。
以下是Bugcrowd的LevelUp #03在线会议的直播录音
演示视频:
如果你不喜欢看视频那么以下内容将简要概述何时以及如何使用它。
Turbo Intruder是一个用于发送大量HTTP请求并会分析其结果的Burp Suite扩展。它旨在补充Burp Intruder以处理需要特殊速度持续时间或复杂性的攻击。
特性
高速 – Turbo Intruder使用从头开始手动编码的HTTP stack并充分考虑其执行速度。因此在许多目标上它甚至可以超过那些流行的异步Go脚本。
可扩展 – Turbo Intruder可实现平面内存使用以及可靠的多日攻击。它也可以通过命令行在headless环境中运行。
灵活 – 使用Python配置攻击。这样可以处理复杂的需求例如签名请求和多步攻击序列。此外自定义HTTP stack意味着它可以处理破坏其他库的格式错误请求。
方便 – 无意义的结果可通过改编自Backslash Powered Scanner 的高级衍射算法自动过滤掉。这意味着你只需通过两次单击就可以启动攻击并获得有用的结果。
虽说它的优点很多但不可否认的是它使用起来并不容易且网络堆栈也不像核心Burp那样可靠和经过实战考验。因此Turbo Intruder主要是为向单个主机发送大量请求而设计的。如果你想向多个主机发送一个请求那我推荐你使用ZGrab。
使用入门
使用Extender选项卡下的BApp Store将Turbo Intruder安装到Burp Suite中。如果你更喜欢从源码构建它请使用gradle build fatJar然后通过Extender->Extensions->Add加载src/build/libs/turbo-intruder-all.jar即可。
要使用它只需选中你要注入的区域然后右键单击并“发送至Turbo Intruder”
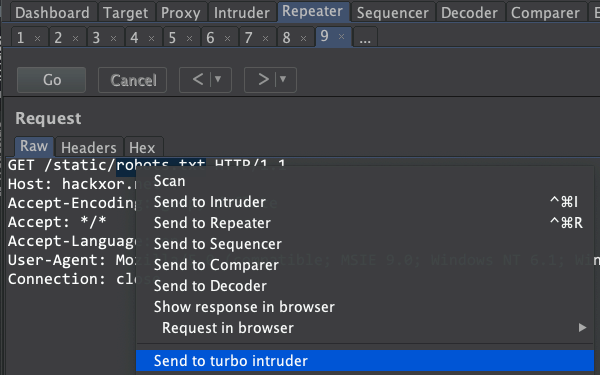
这将打开一个包含你请求的窗口和一个Python代码段如下所示
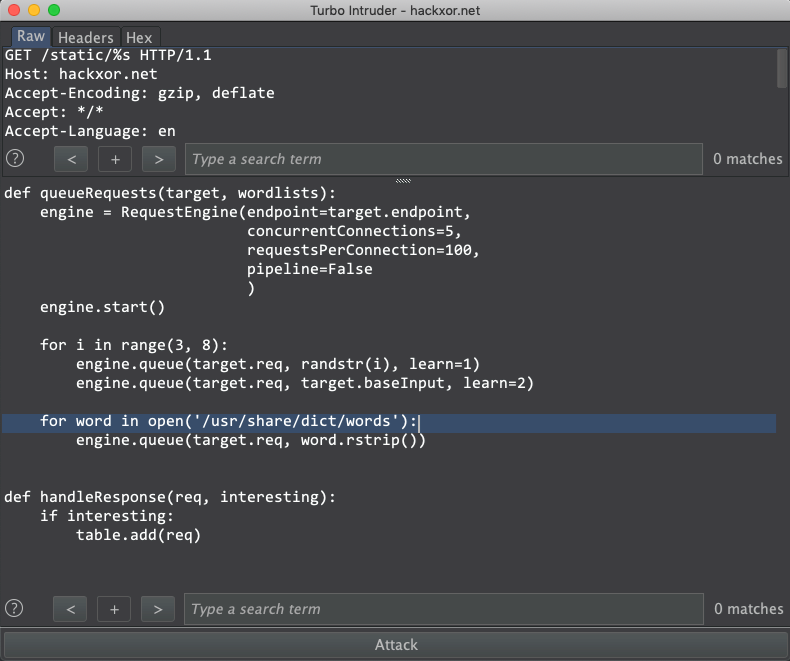
你可以根据攻击要实现的目标自定义该代码段。
基础使用
可以看到你选中的请求区域已被替换为’s’ – 这是你的payload将被放置的位置。首先这里你可能想将 ‘/usr/share/dict/words’更改为你自己的单词列表。除此之外默认脚本应该是开箱即用的一个用例。
顺带一提Turbo Intruder通过网络级效率实现了速度因此即使在网络连接不良时也会保持相对的性能我的第一个现场演示是在一个酒吧地下室使用从隔壁咖啡店借来的wifi完成的并且仍然达到了每秒几百个请求的速度。
这意味着目标网站可能是其运行速度的限制因素。由于它使用少量的并发连接因此不太可能导致服务器的连接池被消耗且没有其他人可以连接的典型DoS情况。但是针对资源密集型页面可能会使服务器变慢并影响个人的访问速度因此建议在攻击期间监控应用程序性能。
过滤无用的结果
在Turbo Intruder中响应不会自动放入结果表中。 而是调用’handleResponse’函数你可以在其中决定是否将响应添加到表中。以下是一个简单的例子
def handleResponse(req, interesting): if '200 OK' in req.response:
table.add(req)编写自定义的响应检查并不总是必要 – 如果你使用’learn’参数队列一些请求那么Turbo Intruder会将这些响应视为无意义的然后根据每个新响应来设置 ‘interesting’ 参数。默认脚本使用该策略。有关此过滤策略的更多信息请查看演示视频。
速度调整
如果速度对于你攻击很重要那么你可能需要调整pipelinerequestsPerConnection和concurrentConnections参数。你的目标应该是找到最大化RPS每秒请求数值同时保持Retries计数器接近0。这里的最佳值取决于服务器但到目前为止我对远程服务器的最大速度为30,000 RPS。你可以通过将方法从GET更改为HEAD通过减少请求/缩短响应来实现进一步的速度增益。
查找竞争条件
默认脚本使用流式攻击样式这对于最小化内存使用非常有用但不适合查找竞争条件。要查找竞争条件你需要确保所有请求都尽可能的在一个小窗口中命中目标这可以通过在启动请求引擎之前队列所有请求来完成。你可以在race.py找到一个示例。
内置的单词列表
Turbo Intruder有两个内置的单词列表 – 一个用于启动长期运行的暴力攻击另一个包含在范围内代理流量中观察到的所有单词。后一个词表可能会导致一些非常有趣的发现通常需要手动测试来识别。你可以在specialWordlists.py中查看如何使用它们。
命令行使用
有时你可能想要从服务器运行Turbo Intruder。为了支持headless使用它可以直接从jar启动而无需Burp。你可以从发行版中获取一个预先构建的turbo.jar文件。运行命令如下
java -jar turbo.jar <scriptFile> <baseRequestFile> <endpoint> <baseInput>例如
java -jar turbo.jar resources/examples/basic.py resources/examples/request.txt https://example.net:443 foo虽然支持命令行但我并不建议大家去专门使用。不然你会感觉有些糟糕。
交换请求引擎
Turbo Intruder的架构允许你通过RequestEngine的可选’engine’参数在不同的网络堆栈之间进行交换。默认情况下它将使用快Engine.THREADED选项但在某些情况下你可能更喜欢使用Engine.BURP来利用Burp的稳定性或上游代理处理。早期版本的Turbo Intruder也有基于Apache HttpComponents构建的异步和HTTP2引擎但它们的可靠性远远低于线程引擎并且在大多数机器上实际并没有更快所以我将它们封装了起来。
调试问题
如果统计面板中的 ‘failed’ 计数器开始快速增加则可能是你的脚本、目标网站或Turbo Intruder的网络堆栈的问题。如果你对帮助改进该工具感兴趣我已经编写了一个调试脚本来帮助你识别并报告可能的问题根源。
结语
像以往一样我还有很多改进Turbo Intruder的计划。我们还计划最终将Turbo Intruder网络堆栈的一些功能引入到核心Burp Suite工具中。另外我正在参加2018年十大网络黑客技术的评选活动。如果你可以为我投上一篇那我将万分感谢祝你好运Good luck
*参考来源:portswigger,FB小编secist编译,转载自FreeBuf