前段时间漏洞之王Struts2日常新爆了一批漏洞,安全厂商们忙着配合甲方公司做资产扫描,漏洞排查,规则大牛迅速的给出”专杀”规则强化自家产品的规则库。这种基于规则库的安全防御总是处于被动的,所以趁着小假期对机器学习应用于威胁检测的这块做了些研究整理了下笔记,以方便大家日后交流学习。
本文参考了国外的一篇博文,英语好的可以直接看下原文,在这里记录了下研究检测模型实现的过程,因为也是最近才接触机器学习这块,有啥问题请大牛们指出。
先说重点,这篇文章使用逻辑回归的方式建立检测模型,对未知的 URL 进行恶意检测。
模型建立的整体思路如下:
1. 分别拿到正常请求和恶意请求的数据集。
2. 对无规律的数据集进行处理得到特征矩阵。
3. 使用机器逻辑回归方式使用特征矩阵训练检测模型。
4. 最后计算模型的准确度,并使用检测模型判断未知 URL 请求是恶意的还是正常的。
0×00 收集数据集
我们需要分别拿到恶意的数据集和正常的数据集用来后期处理,在这里恶意的数据集来自 https://github.com/foospidy/payloads 中的一些 XSS SQL注入等攻击的payload,结合github上一些知名仓库的payload,一共整理出 50000 条恶意请求作为恶意的数据集;正常请求的数据集来自于 http://secrepo.com/ , 攻击1000000条日志请求(资源有限,假定认为这些数据全部都是正常的请求,有精力可以进行降噪处理,去除异常的标签数据)。
恶意请求部分样如下:
/top.php?stuff='uname >q36497765 #
/h21y8w52.nsf?<script>cross_site_scripting.nasl</script> /ca000001.pl?action=showcart&hop=\"><script>alert('vulnerable')</script>&path=acatalog/
/scripts/edit_image.php?dn=1&userfile=/etc/passwd&userfile_name= ;id;
/javascript/mta.exe
/examples/jsp/colors/kernel/loadkernel.php?installpath=/etc/passwd\x00
/examples/jsp/cal/feedsplitter.php?format=../../../../../../../../../../etc/passwd\x00&debug=1
/phpwebfilemgr/index.php?f=../../../../../../../../../etc/passwd
/cgi-bin/script/cat_for_gen.php?ad=1&ad_direct=../&m_for_racine=</option></select><?phpinfo();?> /examples/jsp/cal/search.php?allwords=<br><script>foo</script>&cid=0&title=1&desc=1 正常请求部分样本:
/rcanimal/ /458010b88d9ce/ /cclogovs/ /using-localization/ /121006_dakotacwpressconf/ /50393994/ /166636/ /labview_v2/ /javascript/nets.png /p25-03/ /javascript/minute.rb
/javascript/weblogs.rss
/javascript/util.rtf 0×01 计算特征矩阵
无论是恶意请求数据集还是正常请求数据集,都是不定长的字符串列表,很难直接用逻辑回归算法对这些不规律的数据进行处理,所以,需要找到这些文本的数字特征,用来训练我们的检测模型。
在这里,我们使用 TD-IDF 来作为文本的特征,并以数字矩阵的形式进行输出。
TD-IDF 是一种用于资讯检索与文本挖掘的常用加权技术,被经常用于描述文本特征。
实际上是:TF * IDF,TF 词频(Term Frequency),IDF 逆向文件频率(Inverse Document Frequency)。
这里简单说下他们的概念,感兴趣的可以搜搜资料:
TF表示词条在某文档中出现的频率。
IDF的主要思想是:如果包含词条的文档越少,则 IDF越大,说明该词条具有很好的类别区分能力。
TF-IDF 倾向于过滤掉常见的词语,保留重要的词语。
要计算 TD-IDF 之前首先需要对 每个文档(URL请求)的内容进行分词处理,也就是需要定义文档的词条长度,这里我们选择长度为3,可以根据模型的准确度对这个参数进行调整。
比如:
// URL 请求
// 经过分词后
['www','ww.','w.f','.fo','foo','oo.','o.c','.co','com','om/','m/1']
下面对所有 URL 请求计算出 TD-IDF 特征矩阵,输出格式基本上是下面的样子:
(0, 31445) 0.0739022819816 (0, 62475) 0.0629894240925 (0, 46832) 0.0589025342739 (0, 77623) 0.0717033170552 (0, 35908) 0.0882896248394 : 省略 :
(1310503, 17869) 0.245096903287 (1310503, 7490) 0.350336780418 (1310504, 8283) 0.344234609884 (1310504, 72979) 0.265488228146 (1310504, 67485) 0.253863271567 (1310504, 37730) 0.328153786399 可以看出特征矩阵的元素由[(i,j) weight] 三个元素组成,
在矩阵中:
i 对应于集合中的文档编号,j对应于term编号(或者说是词片编号)
矩阵元素[(i,j) weight] 表示编号 为 j 的词片 在编号为 i 的文档下的 fd-idf 值(weight)。
比如: (0, 31445) 0.0739022819816 表示词片编号31445的在第0号文档的权值是 0.0739022819816
0×02 训练检测模型
现在有了特征矩阵作为训练的数据集,可以先从中取出一少部分数据(大约占总数据的5%,可以自行指定)用来测试已经训练好的模型的准确率。至于如何取出测试数据,可以直接使用scikit-learn提供的 train_test_split 方法对原始数据集进行分割。
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.05, random_state=42)
// x 是原始的特征矩阵 y 是 该条矩阵的分词对应的结果输出(正常是0 恶意是1)的列表
// random_state 是随机说种子,test_size 是测试样本所占比例
// x_train,x_test 分别是用于训练模型和测试模型准确度的特征矩阵
// y_train 和 y_test 是与 x_train,x_test 对应的结果输出列表 有了训练数据,可以直接使用逻辑回归的方法来训练我们的模型,这一步需要电脑花点时间对数据进行处理,但是我们只需要调用 scikit-learn 定义一个逻辑模型实例,然后调用训练方法,传值训练数据即可,代码如下:
lgs = LogisticRegression()
lgs.fit(x_train, y_train) 0×03 测试模型效果
经过训练之后使用 lgs 实例的 score 方法 选择一批测试数据来计算模型的准确度,至于测试数据(x_test,y_test)我们已经在上一步中分割得到
lgs.score(x_test, y_test) 检测模型的准确度:
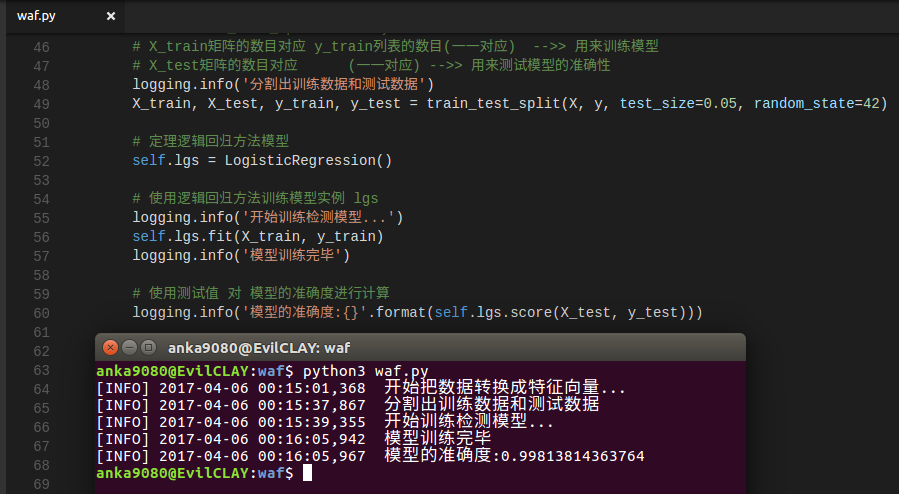
同时,可以调用 lgs.predict 的方法对 新的 URL 是否是恶意的进行判定。
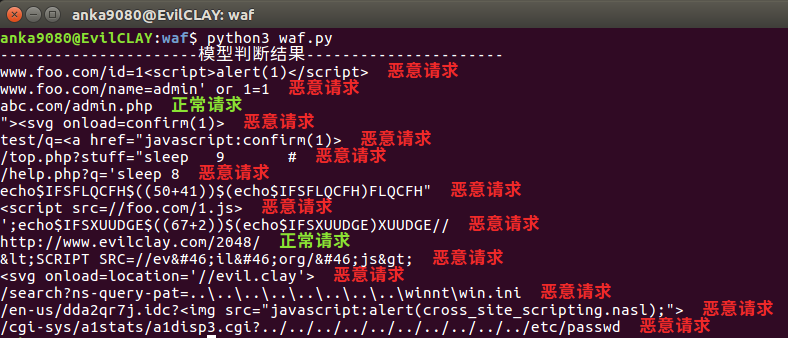
x_predict = ['待预测URL列表'] x_predict = vectorizer.transform(x_predict) res = lgs.predict(x_predict) 在这里随机选取一些 URL 进行预测,判断的结果如下:
0×04 总结
本文的目的是希望从代码的角度上分析如何机器学习算法来训练URL恶意检测模型,当然训练检测模型的方式有许多种,比如 SVM 或是其他机器学习算法,想了解 SVM 的可以看兜哥先前发的文章。
基于逻辑回归的恶意 URL 检测很依赖于训练数据集,有必要保证原始数据集尽可能的减少噪点(异常数据),以及每条数据之间尽可能的减少关联性。
若能拿到自身业务中确定正常或者威胁的请求数据作为训练数据集训练出的模型应该也更加适用于当前环境的检测。
同时作为监督式学习,可以定期把检测出确定威胁的请求放入原始数据集中,对检测模型进行优化,效果会更好。
源码地址:
https://github.com/exp-db/AI-Driven-WAF
参考:
1. http://www.freebuf.com/articles/web/126543.html
2. http://fsecurify.com/fwaf-machine-learning-driven-web-application-firewall/
3. http://scikit-learn.org/stable/modules/feature_extraction.html#text-feature-extraction
*原创作者:Anka9080@Sec-Wiki