0×01.前言
Github作为一个代码托管平台,有着海量的开源代码和许多开发者。在代码上传时,有些开发者缺乏安全意识,会在不经意间泄露自己的密码或者密钥。本文以这里为切入点,介绍一个检索代码信息的小爬虫以及在写爬虫时的一些奇技淫巧。
0×02.github信息泄露
正如前言所述,缺乏安全意识的开发者会造成这个问题。不止web路径下的.git目录会泄露信息,在托管的开源代码中也会产生信息泄露。例子很多,比如php连接数据库的配置文件泄露,那么可能数据库帐号密码都泄露了,任何人都可以访问这个数据库。再比如通向内网的帐号密码,管理员帐号密码乃至ssh密钥。
api,即应用程序编程接口。众所周知,http是无状态协议,为了将用户区分开引进了cookie机制。有许多厂商,提供了api这个接口供用户调取业务,为了区分用户引进了token,比如'https://example.com/get?info=xxx&token=xxx'
而我比较喜欢做的事就是,在github上找api的密钥。因为相比与帐号密码,这个不但泄露的更多,而且也更难以注意察觉,并且我们调用方便。比如查询whois信息,子域名检测等等,很多安全厂商提供了api接口,所以如果你没有密钥,不妨试试这个github信息泄露的方法。
shodan可能很多安全从业者都知道,这是一个很强大的搜索引擎。下文我会以爬取github上的shodan api密钥为例子,写一个简单的小爬虫。
0×03.github搜索结果爬取
1.shodan api格式
首先访问https://developer.shodan.io/api,这是shodan的api文档,我们可以看到api请求格式为https://api.shodan.io/shodan/host/{ip}?key={YOUR_API_KEY}。之后我们就可以在github上搜索”https://api.shodan.io/shodan/host/ key=”来看看。
结果如图:
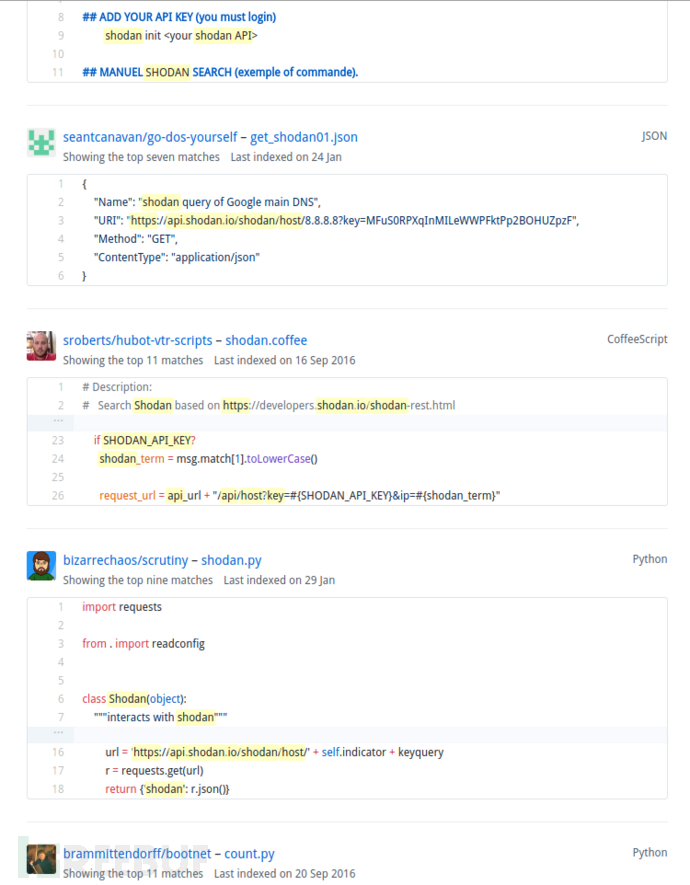
可以看到已经有人不小心泄露自己的密钥了,虽然还有很多人没有。
2.github信息收集
虽然github有提供api,但是对代码检索功能有限制,所以我们这里不使用api。
首先进行搜索我们需要有一个登录状态,大家可以注册一个小号,或者是使用大号,这个没关系的。
登录状态我们可以使用cookies,也可以直接登录,我们这里说直接登录。
首先F12抓包可以看到整个登录流程,即访问github.com/login,之后将表单的值传递给github.com/session。整个流程非常清晰。
代码如下:
import requests
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0', 'Referer': 'https://github.com/', 'Host': 'github.com', 'Upgrade-Insecure-Requests': '1',
}
payload = {'commit': 'Sign in', 'login': 'xxxxxx@xxxx.xxx', 'password': 'xxxxxx'}
r = requests.get("https://github.com/login", headers=headers)
_cookies = r.cookies
r = requests.post("https://github.com/session", headers=headers, data=payload, cookies=_cookies)
如上可不可以呢?仔细分析整个流程,实际上,表单值中还有一个authenticity_token,我们要先抓取到这个值,然后传递给表单。
抓取函数如下:
from lxml import etree def get_token(text): #<input name="authenticity_token" value="Wwc+VXo2iplcjaTzDJwyigClTyZ9FF6felko/X3330UefrKyBT1f/eny1q1qSmEgFfTm0jKv+HW7rQ5hYu84Qw==" type="hidden"> html = etree.HTML(text)
t = html.xpath("//input[@name='authenticity_token']") try:
token = t[0].get('value') except IndexError:
print("[+] Error: can't get login token, exit...")
os.exit() except Exception as e:
print(e)
os.exit() #print(token) return token
payload['authenticity_token'] = get_token(r.content)
现在我们代码还有什么缺点呢,我觉得就是对cookies的处理不够优雅。requests有一个神奇的类requests.session(),可以为每次请求保存cookies,并应用于下次请求。
在官方文档我们可以找到http://www.python-requests.org/en/master/user/advanced/#session-objects。

所以这里我们可以使用requests.session对代码进行优化,即:
import requests
session = requests.Session()
r = session.get("https://github.com/login", headers=headers)
payload['authenticity_token'] = get_token(r.content)
r = session.post("https://github.com/session", headers=headers, data=payload) 获取登录状态后,我们就可以进行搜索,之后列举出信息。
这里采用lxml进行信息提取,xpath很简单,不多说,代码如下:
from lxml import etree
words = "https://api.shodan.io/shodan/host/ key=" url = ("https://github.com/search?p=1&q=%s&type=Code" % words)
r = session.get(url, headers=headers)
html = etree.HTML(r.text)
block = html.xpath("//div[@class='code-list-item col-12 py-4 code-list-item-public ']")
print("[+] Info: get item: %i" % len(block))
codes = html.xpath("//div[@class='code-list-item col-12 py-4 code-list-item-public ']/div[@class='file-box blob-wrapper']/table[@class='highlight']/tr/td[@class='blob-code blob-code-inner']")
nums = html.xpath("//div[@class='code-list-item col-12 py-4 code-list-item-public ']/div[@class='file-box blob-wrapper']/table[@class='highlight']/tr/td[@class='blob-num']/a") if len(codes) == len(nums):
print("[+] Info: start get data, waiting")
lines = []
strs = None for i in range(len(nums)): #print(etree.tostring(codes[i], method='text')) try:
text = etree.tostring(codes[i], method='text') except UnicodeEncodeError:
print("[+] UnicodeEncodeError of a result, jump...") continue if nums[i].text == '1': if strs is not None:
lines.append(strs)
strs = text else:
strs = "%s \\n %s" % (strs, text)
lines.append(strs) else:
print("[+] Error: wrong number get for codes lines, exit")
print("info : %s" % lines)
print("total num of info get: %i" % len(lines)) 接下来是正则部分,信息抓取下来后,怎么筛选出我们需要的信息呢?靠的就是这里。
因为我们知道shodan api以http的形式,把shodan的token带入了参数中。简单的以get方法为例,可能是?key=xxx&host=xxx、?hosy=xxx&key=xxx&ip=xxx或者?host=xxx&key=xxx等等形式,所以我们构造正则为 key=的形式,然后尝试匹配key的末尾,可能是'、"、&。
代码如下:
import re
pattern = re.compile('key=(.*)[&|"|\']') for a in lines:
strs = re.findall(pattern, str(a)) if len(strs) > 0: #print(strs[0].split('"')[0]) results = strs[0].split('"')[0]
results = results.split('&')[0]
results = results.split('\'')[0] if results == '': continue print(results) 用一个简单的多线程,多爬取几页可以看到输出:
D32FBKHYYqETSf4bIdmurM7xoZA74FnL
E48kKXIaCpuKq4nsTJCglvd9o4y8oBni
${SHODAN_API_KEY}
AR7LzKvBGZNaXlgkYCg4Z9y3x5lEO352
%s
${PINCH.USERDEFINED.api_key.value} {ShodanAPIKey} {YOUR_API_KEY} %s
$SHODAN_API_KEY
MFuS0RPXqInMILeWWPFktPp2BOHUZpzF #{SHODAN_API_KEY} D32FBKHYYqETSf4bIdmurM7xoZA74FnL
$SHODAN_API_KEY
MFuS0RPXqInMILeWWPFktPp2BOHUZpzF #{SHODAN_API_KEY} ${PINCH.USERDEFINED.api_key.value}
E48kKXIaCpuKq4nsTJCglvd9o4y8oBni {YOUR_API_KEY} %s
${SHODAN_API_KEY}
AR7LzKvBGZNaXlgkYCg4Z9y3x5lEO352 虽然已经有了输出,但是注意到并不是所有输出都符合要求,有的甚至只是一个变量名。
其实到这里已经结束了,shodan api长度为32,只要验证长度就可以得到密钥了。但是本着精益求精的精神,我们将会编写正则表达式,进一步的获取信息。
从输出可以看到,除了输出token,还有%s和变量名称两种形式。熟悉python的人可能知道,%s是python中的格式化输出。
我们首先去除特殊符号data = re.findall(pattern1, results)[0],之后判断字符串类型:
if data == 's':
print("python") elif len(data) < 32:
print("value") else:
print(data) 这里我们顺利区分开了python的输出、值为token的变量和token。
下一步我们尝试得到变量的值,即token。我们假设变量的值就在搜索结果中,即key=value的形式。
由于上一步中已经得到了变量名称data,所以构建正则如下:
pattern0 = re.compile("%s[=|:](.*)[\"|']" % data[:6])
results = re.findall(pattern0, a.replace(' ','')) if len(results) > 0:
results = results[0].split('\'')[0]
print(results.split('"'))
我们可以获得输出比如['sys.argv[1]\\n\\n']。
然后是对python格式化输出%s的解析。通常%s格式化输出为print("%s" % strs)或者print("%s,%s" % (strs, strs))的形式。所以构建正则如下:
pattern2 = re.compile('%\([\w|\.|,]+')
results = re.findall(pattern2, a.replace(' ',''))
lists = [] for i in results:
i = i.replace('%(', '')
i = i.split(',')
lists.extend(i)
lists = set(lists)
这里我们首先提取变量名称strs,之后做了去重操作。
既然得到了变量名词,我们可以仿照上一步,得到变量的值。
再次运行结果如下:
['//api.bintray.com/packages/fooock/maven/jShodan/images/download.svg)](https://bintray.com/fooock/maven/jShodan/_latestVersion)[]( https://android-arsenal.com/details/1/5312)\\n']
D32FBKHYYqETSf4bIdmurM7xoZA74FnL
D32FBKHYYqETSf4bIdmurM7xoZA74FnL
E48kKXIaCpuKq4nsTJCglvd9o4y8oBni
AR7LzKvBGZNaXlgkYCg4Z9y3x5lEO352
['//developer.shodan.io](https://developer.shodan.io)\\n']
MFuS0RPXqInMILeWWPFktPp2BOHUZpzF
['//api.shodan.io/shodan/host/search?key=%s&query=hostname:%s&facets={facets}', '%(\\n']
MM72AkzHXdHpC8iP65VVEEVrJjp7zkgd
['OPTIONAL)],\\n\\n']
0fTS2YJPZAOSQHnC7kSEI06LrTg7pPcV 0×04.爬虫技巧
1.调试爬虫
有时我们写完爬虫后,会发现结果并不是我们想要的,我们就想知道中间出了什么问题。
最直观的,直接输出代码print(req.content),或许复杂一点,输出成html文件:
def see(text): with open("./t.html", "w") as f:
f.write(text)
see(req.content) 大家可能知道,我们会用burp suite、fiddle来进行移动端的抓包分析。同样的,在这里,我们也可以通过代理,对爬虫进行分析。这里我使用的是burp suite。
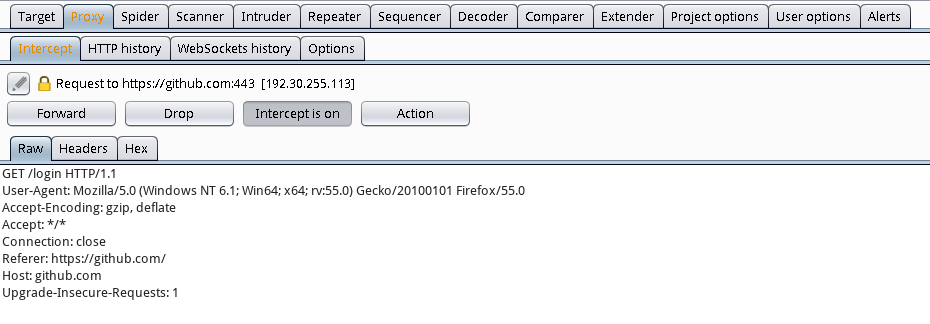

我们不仅可以实时分析请求,也可以在history里分析请求。
这里以requests为例,我们可以使用代理设置,官方文档如图:
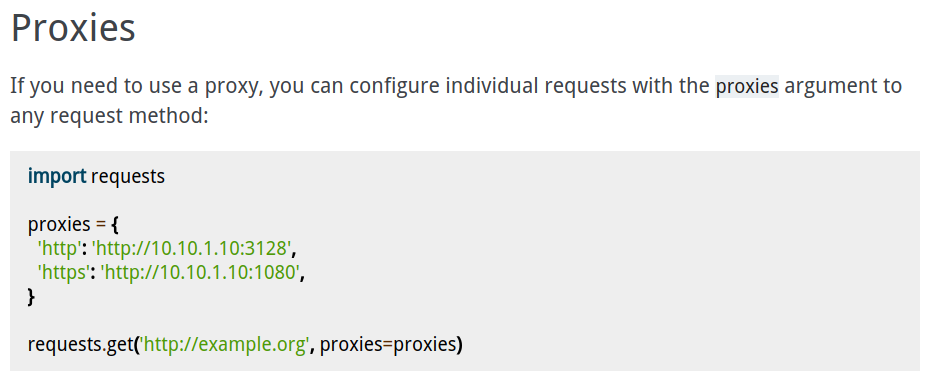
proxies = { 'http': 'http://127.0.0.1:8080', 'https': 'http://127.0.0.1:8080',
}
r = session.get("https://github.com/login", headers=headers, proxies=proxies) 但是大家应该知道,在浏览器中使用burp suite对https进行分析的时候,需要导入证书。因为https会对证书进行验证,而burp suite不属于可信证书,所以需要导入。但是这里我们怎么导入证书呢?
很简单,只需要简单的加一个参数verify即可。这个verify的意思为,不对证书进行验证。
r = session.get("https://github.com/login", headers=headers, verify=False, proxies=proxies) 2.保存状态
为了不需要每次都要登录,我们可以保存cookie到文件,下次直接读取cookie就好了。代码如下:
# 从文件读入cookie with open('./cookies.txt', 'rb') as f:
cookies = requests.utils.cookiejar_from_dict(pickle.load(f))
session.cookies=cookies # 保存cookie with open('./cookies.txt', 'wb') as f:
pickle.dump(requests.utils.dict_from_cookiejar(session.cookies), f) 0×05.总结
这次只是以shodan api为例子,提醒大家注意github信息泄露,也给想要爬取github敏感信息的人抛个砖。不只是shodan api,github上有更多的api等待你去挖掘。只需要改改正则,调试一下,你也有了自己的api爬取爬虫。
附录
代码如下(也可以访问这个私密gist):
#coding:utf-8 import requests import re from lxml import etree import os import io import pickle import threading import warnings
warnings.filterwarnings('ignore')
session = requests.Session()
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0' , 'Referer': 'https://github.com/' , 'Host': 'github.com', 'Upgrade-Insecure-Requests': '1',
}
payload = {'commit': 'Sign in' , 'login': 'xxxxx@xxx.xxx', 'password' : 'xxxxxx'}
proxies = { 'http': 'http://127.0.0.1:8080' , 'https': 'http://127.0.0.1:8080' ,
} def see(text): with open("./t.html" , "w") as f:
f.write(text) def get_token(text): # html = etree.HTML(text)
t = html.xpath("//input[@name='authenticity_token']") try:
token = t[0].get('value' ) except IndexError:
print("[+] Error: can't get login token, exit...")
os.exit() except Exception as e:
print(e)
os.exit() #print(token) return token def get_cookie(session): if not os.path.exists("./cookies.txt" ):
r = session.get("https://github.com/login" , headers=headers)#, verify=False, proxies=proxies) payload['authenticity_token'] = get_token(r.content)
r = session.post("https://github.com/session" , headers=headers, data= payload)#, verify=False, proxies=proxies) #print(r.cookies.get_dict()) #see(r.text) else: with open('./cookies.txt' , 'rb') as f: try:
cookies = requests.utils.cookiejar_from_dict(pickle.load(f)) except TypeError:
os.remove("./cookies.txt") return get_cookie(session)
session.cookies=cookies return session def search(url, session): r = session.get(url, headers=headers) #, verify=False, proxies=proxies) html = etree.HTML(r.text)
block = html.xpath("//div[@class='code-list-item col-12 py-4 code-list-item-public ']" ) #print("[+] Info: get item: %i" % len(block)) codes = html.xpath("//div[@class='code-list-item col-12 py-4 code-list-item-public ']/div[@class='file-box blob-wrapper']/table[@class='highlight']/tr/td[@class='blob-code blob-code-inner']" )
nums = html.xpath("//div[@class='code-list-item col-12 py-4 code-list-item-public ']/div[@class='file-box blob-wrapper']/table[@class='highlight']/tr/td[@class='blob-num']/a" ) if len(codes) == len(nums):
lines = []
strs = None for i in range (len(nums)): #print(etree.tostring(codes[i], method='text')) try:
text = etree.tostring(codes[i], method= 'text') except UnicodeEncodeError: #print("UnicodeEncodeError") continue if nums[i].text == '1' : if strs is not None:
lines.append(strs)
strs = text else:
strs = "%s \n %s" % (strs, text)
lines.append(strs) else:
print("[+] Error: wrong number get for codes lines, exit")
pattern = re.compile('key=(.*)[&|"|\']')
pattern1 = re.compile("\w+")
pattern2 = re.compile('%([\w|.|,]+') for a in lines: #a = a.replace(' ','') strs = re.findall(pattern, str(a)) if len(strs) > 0:
results = strs[0].split('"' )[0]
results = results.split('&')[ 0]
results = results.split('\'')[ 0] if results == '' : continue try:
data = re.findall(pattern1, results)[0] except IndexError:
print(results) continue if data == 's' :
resulresults = re.findall(pattern2, a.replace(' ', ''))
lists = [] for i in results:
i = i.replace('%(', '' )
i = i.split(',')
lists.extend(i)
lists = set(lists) for i in lists:
pattern0 = re.compile("%s=|:[\"|']" % i[:6])
results = re.findall(pattern0, a.replace(' ', '')) if len(results) > 0:
results = results[0].split('\'' )[0]
print(results.split('"')) #print(a) elif len(data) < 32:
pattern0 = re.compile("%s=|:[\"|']" % data[:6])
results = re.findall(pattern0, a.replace(' ', '')) if len(results) > 0:
results = results[0].split('\'' )[0]
print(results.split('"')) #print(a) else:
print(data)
words = "https://api.shodan.io/shodan/host/ key=" session = get_cookie(session)
threads = [] for i in range( 1, 21):
url = "https://github.com/search?p= %i&q=%s&type=Code" % (i, words)
t=threading.Thread(target = search, args = (url, session))
t.start()
threads.append(t) for t in threads:
t.join()
threads = [] for i in range( 21, 41):
url = "https://github.com/search?p= %i&q=%s&type=Code" % (i, words)
t=threading.Thread(target = search, args = (url, session))
t.start()
threads.append(t) for t in threads:
t.join() with open('./cookies.txt' , 'wb') as f:
pickle.dump(requests.utils.dict_from_cookiejar(session.cookies), f) *本文原创作者:grt1stnull