写在前面
信息收集对于渗透测试来说是很重要的,是渗透测试的前期准备工作,俗话说知己知彼,才能百战不殆。掌握了对目标的足够信息,我们才能更好地开展渗透测试。
信息收集的方式可以分为两种:主动信息收集和被动信息收集
主动信息收集:是指通过直接和目标访问、各种工具直接对目标网站进行检测。直接使用工具对网站进行信息探测可以获得较多较全的信息,但是可能会被目标主机发现,对你的可疑行为进行记录,分析,可能会对后期的渗透工作产生影响。
被动信息收集:是指通过各种的在线网站等第三方服务对网站进行信息收集。比如通过用Google Hacking,shodan、fofa等搜索引擎对目标进行信息探测,虽然获得的信息可能不多,但是不存在被目标发现的可能。
没有一种方式可以做到面面俱到,每个方式都会存在自己的优势和劣势。我们需要学会各种工具搭配使用,取长补短,对目标进行多次隐秘而有效的探测,既获得自己想要的信息,又不让目标对我们的可疑行为进行记录,分析,最后完成对目标网站完整的信息收集报告。
1.信息收集的的由来——黑客攻击模型
渗透测试的具体流程有:
收集目标的信息
↓
分析目标,存在哪些弱点,是可以进行攻击的
↓
实施攻击,多种攻击手段(ddos,植入木马,获取shell等)
↓
留后门,方便再次进入(植入木马,修改系统配置文件,IP报文,ICMP报文)
↓
清理入侵记录(对系统的操作都会记录在系统日志信息里,需要清理信息)
如图所示:

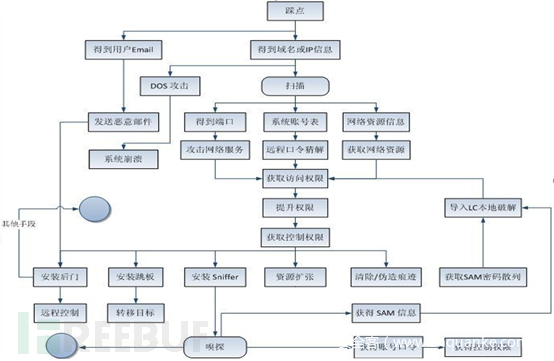
信息收集是攻击的第一步,俗称踩点,就是收集目标的各种信息。渗透测试最重要的阶段之一就是信息收集。为了启动渗透测试,用户需要收集关于目标网络资产等信息。现实环境中收集的信息越多,渗透测试成功的概率也就越高。
2.信息收集的基本思路
废话不多说,来看图
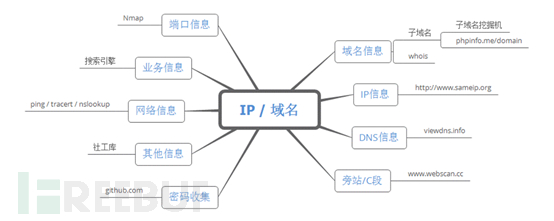
2.1.域名与IP信息
域名系统(Domain Name System缩写DNS,Domain Name被译为域名)是互联网的一项核心服务。它作为可以将域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网,而不用去记住能够被机器直接读取的IP地址。IP地址较为难记,而域名较为好记,这样人们想访问一个网站就轻松许多。
域名是由一串用点分割的名字组成,在Internet上的某台计算机或计算机组的名称,用于在数据传输时对计算机的定位标识(有时也指地理位置)。注意:当前,对于每一级域名长度的限制是63个字符,域名总长度则不能超过253个字符。
我们浏览网站的过程如下图所示。
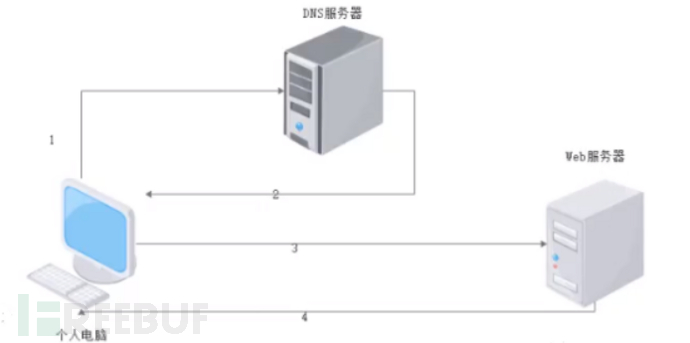
这里举一个例子,sougou.com作为一个域名就和IP地址221.122.82.30相对应。我们可以直接访问221.122.82.30的域名sougou.com来代替IP地址。当我们访问网站的时候,DNS在我们直接调用网站的名字以后就会像sougou.com一样便于人类使用的名字转化成像221.122.82.30一样便于机器识别的IP地址。而如果sougou.com还有自己的子域名edu.sougou.com和www.sougou.com的话,那么edu(教育网)和www(万维网)就是对应的主机名。
2.1.1.使用whois协议
2.1.1.1.介绍
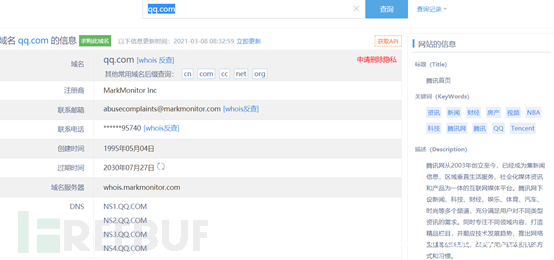
这是一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库(如域名所有人、域名注册商)。
2.1.1.2.查询工具
查询可以借助网上的网页接口简化的线上查询工具。
2.1.2.子域名
2.1.2.1.介绍
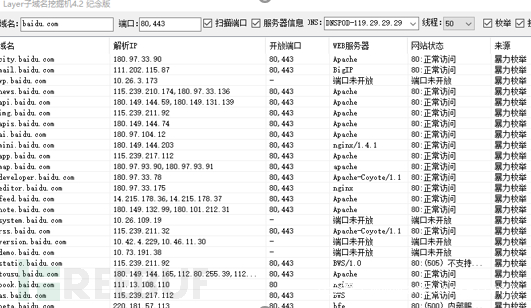
子域名,是顶级域名(.com、.cn、.top)的下一级,域名整体包括两个“.”或包括一个“/”。如:百度顶级域名为baidu.com。其下有news.baidu.com、tieba.baidu.com、zhidao.baidu.com等子域名。收集子域名可以很大程度知道目标所拥有的网站等资产信息。
2.1.2.2.查询工具
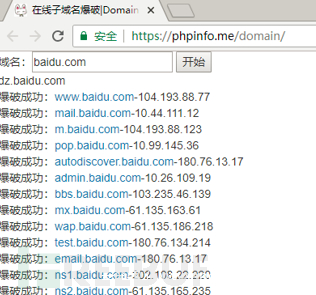
工具可以用子域名挖掘机。
也可以用在线的一些网站
2.1.3.旁站C段
2.1.3.1.旁站
查询旁站指某个服务器同一个IP地址所有域名。
当该网站无法被攻破时,可以试着攻击旁站,进而入侵到服务器,再攻击此网站。
2.1.3.2.C段
查询C段指某个服务器IP地址所在C段IP地址(即/24)的所有域名。
当该网站被攻破,获得服务器的shell,可以监听这一个网段的其他站收发的数据。
2.1.3.3.查询工具
旁站查询:www.webscan.cc

C段查询:https://www.chinabaiker.com/cduan.php
2.1.4.DNS查询
2.1.4.1.介绍
获取域名或者IP地址,并进行反向查找以快速显示同一服务器承载的所有其他域。
2.1.4.2.DNS 查询类型
DNS的查询类型有好多种,比较常用的查询类型有A,PTR,NS,CNAME,MX等五种记录。
以下分别介绍几种类型:
| 记录 | 解释 |
|---|---|
| A | 将域名正向解析为IP,即正向查询 |
| PTR | 将IP反向解析为域名,即逆向查询 |
| CNAME | 查询DNS的别名 |
| NS | 查询解析的名字服务器(Name server) |
| MX | 邮箱服务器查询(可用于判断邮箱是否有效以减低无效邮箱率) |
| AAAA | 将域名解析为IPv6地址 |
| TXT | 一般指为某个主机名或域名设置的说明。常用于网站所有者认证,比如腾讯域名邮箱的所有者认证 |
| SOA | NS用于标识多台域名解析服务器,SOA记录用于在众多NS记录中那一台是主服务器 |
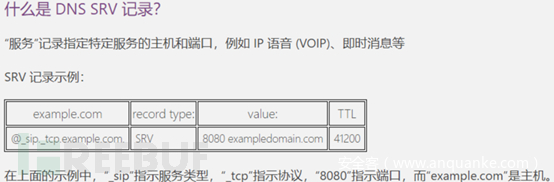
| SRV | 记录指定特定服务的主机和端口 |
2.1.4.3.查询工具
https://myssl.com/dns_check.html
2.1.5.CDN
谈到DNS查询IP地址,这里就要来扯扯真实的IP地址识别了。因为现在有的网站使用了CDN技术,这样我们查询到的IP地址就可能不是真实的IP地址了。
2.1.5.1.介绍
CDN全称是Content Delivery Network,即内容分发网络。其原理如下:某些大型网站在全国都会有很多用户,这些用户常常会向网站发送不同的请求,那么不同地域会具有不同的缓冲服务器来接收用户发送的流量。如果用户发送流量没有任何交互的数据,只是请求首页的话,此时根据用户所在地区来确定访问的高速缓存服务器,高速缓存服务器会返回对应的响应到用户的浏览器当中,比如广东。
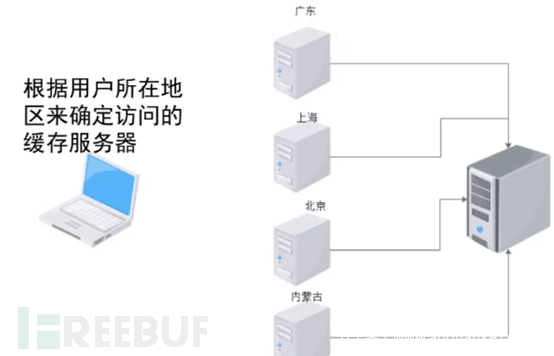
当用户填写数据,需要交互时才会将请求发送到真实的服务器;此时通过广东省的缓存服务器来连接真实服务器。
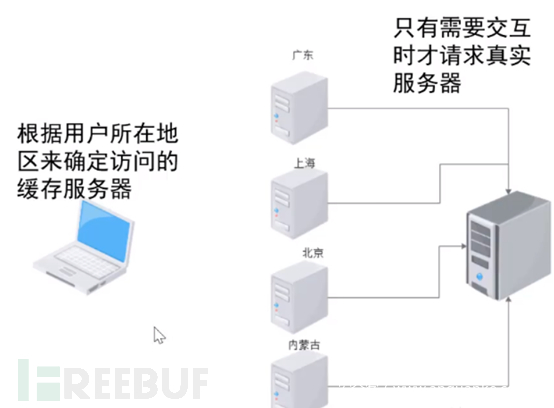
CDN通常存在用户很多的大型流量网站,通过它来解决我们服务器的瓶颈。
2.1.5.2.判断是否存在CDN
可以通过Ping来判断网站是否存在CDN。比如下图所示,可以看到www.baidu.com是存在CDN的
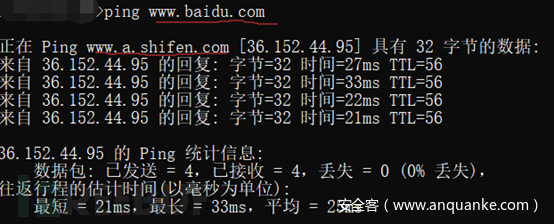
而sougou.com就不存在CDN
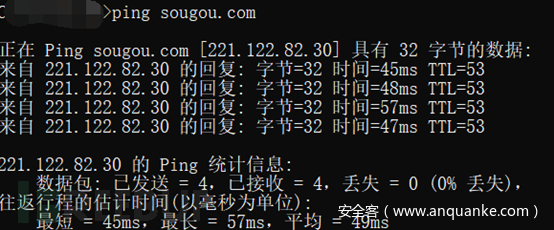
也可以利用在线Ping网站来使用不同地区的Ping服务器来测试目标。这里使用的在线网站是:http://ping.chinaz.com
该网站显示结果如下图所示:
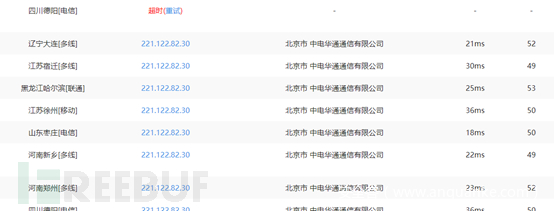
使用不同的Ping服务器,响应的IP地址是相同的。不同的监测点相应的IP地址相同,由此可以推断当前网站没有使用CDN技术。
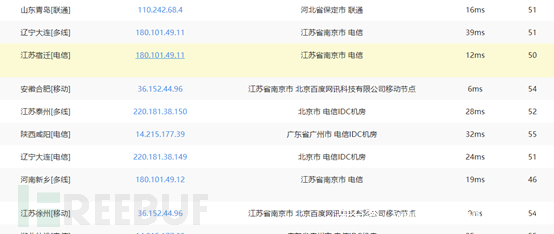
可以看到使用不同的Ping服务器,响应的IP地址是不同的。不同的监测点相应的IP地址不同,由此也可以推断当前网站使用了CDN技术。
2.1.5.3.如何绕过CDN
如果目标网站没有使用CDN的话,这里要想获得目标网站真实的IP地址就很简单了。可以直接在cmd中利用ping获取目标IP地址,也可以使用刚刚的在线ping网站:http://ping.chinaz.com
那么如果确定了网站使用CDN之后,我们应该如何绕过CDN呢?
如果目标网站使用了CDN的话,我们就需要绕过CDN后去获得其真实IP地址,有以下几种方法:
1.通过网站的phpinfo文件:phpinfo.php。该文件泄漏真实IP(其中的
_SERVER["SERVER_ADDR"]或SERVER_ADDR)2.通过phpinfo()泄漏的ip直接无视cdn。
3.分站IP地址,查询子域名:CDN很贵,很有可能分站就不再使用CDN
4.通过国外访问:https://asm.ca.com/en/ping.php
5.通过内部邮箱源:收集到内部邮箱服务器IP地址
6.查询域名解析记录:https://viewdns.info。常常服务器在解析到 CDN 服务前,会解析真实 ip,如果历史未删除,就可能找到。
7.网络空间引擎搜索法。有shodan,fofa,ZoomEye等。我比较常用fofa。
还有许多别的方法,这里就不赘述了。
这里用fofa试一下:
用到的语法为host="www.baidu.com" && domain="baidu.com"
其中host="www.baidu.com"是从url中搜索"www.baidu.com";domain="baidu.com"是搜索根域名带有baidu.com的网站

这里基本上就是网站的真实IP
网络空间引擎很多时候能获取网站的真实ip
再介绍下国内网站https://viewdns.info来查询IP地址:
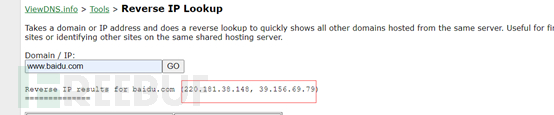
这里还要记得要验证下
2.1.5.4.验证真实IP地址
通过以上的六种方法我们可以获取到很多IP地址,这时我们需要确定哪一个才是真正的IP地址。具体的方法如下:
利用IP地址对Web站点进行访问,如果正常表明是真实IP地址,否则就是假的。
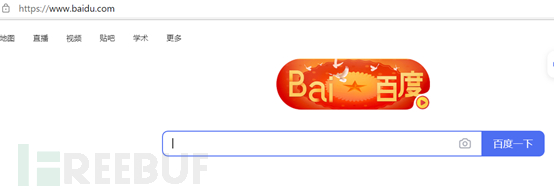
我这里把结果都输入url中,都返回了百度页面,说明是真实的IP地址
2.2.敏感信息
这里可以利用搜索引擎来搜索目标暴露在互联网上的相关信息。比如:SQL注入、数据库文件、服务配置信息,甚至是通过Github找到站点泄露源代码,以及redis等未授权访问、robots.txt等敏感信息,从而达到目的。
2.2.1.Github信息泄露
Web源代码泄露其实不止Github信息泄露这一种,还有好多种,这里看图

我这里重点介绍下Github信息泄露
2.2.1.1.介绍
github.com
github是全球最大的面向开源及私有软件项目的托管平台。
许多企业的开发人员在上传开源代码到github往往忽略了将密码等敏感信息删除导致信息泄露。
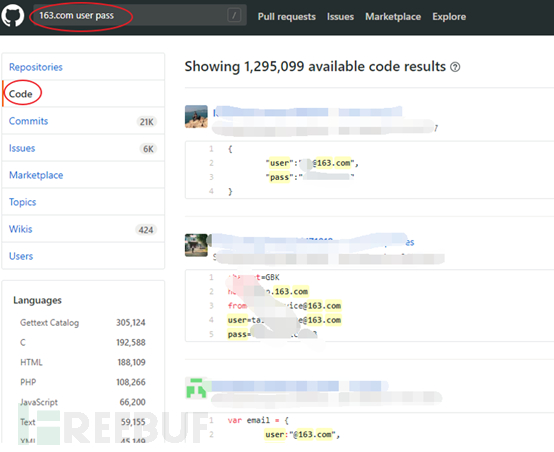
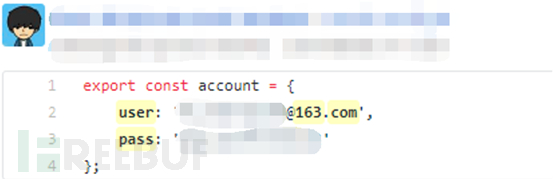
2.2.1.2.方法
通过Github获取数据库泄露信息。
site:Github.com sa password
site:Github.com root password
site:Github.com User ID='sa' 使用Github获取邮件配置信息泄露的信息
site:Github.com smtp @qq.com
site:Github.com smtp 还有许多方法,这里可以自己研究下
2.2.2.Google hacking
2.2.2.1.介绍
搜索引擎都会提供相应搜索语法,通过搜索语法可以快速得到想要的信息。
推荐搜索引擎:必应:bing.com、百度:baidu.com、谷歌:google.com
2.2.2.2.推荐语法
intitle:搜索网站标题含有的关键字
inurl:搜索url含有的关键字
intext:搜索网页正文含有的关键字
site :搜索特定网站和网站域名
filetype:搜索特定文档格式
比如:搜索敏感信息泄露intitle:"index of" admin
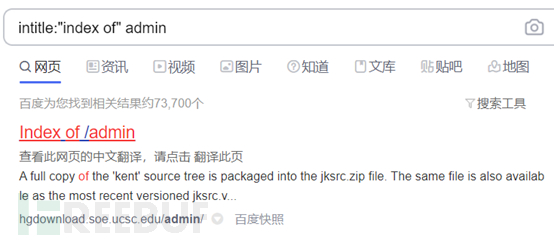
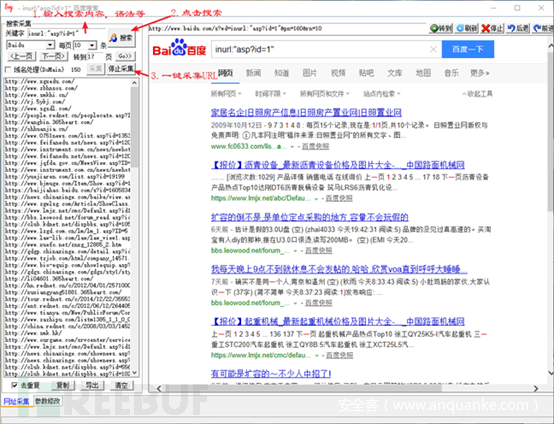
2.2.2.3.配合URL采集器使用
URL采集器:快速切换搜索引擎,快速获得搜索结果。
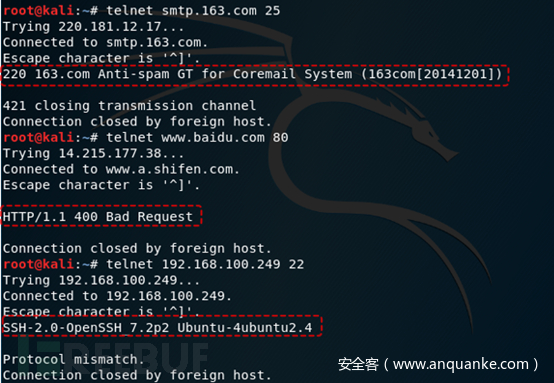
2.2.3.HTTP响应报文信息收集
2.2.3.1.介绍
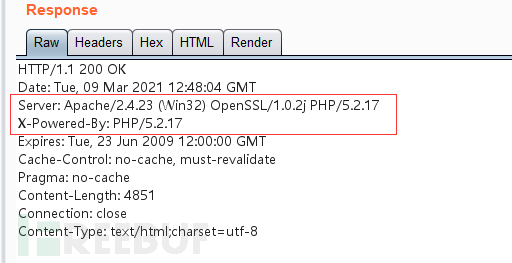
通过HTTP或HTTPS访问目标网站后,HTTP/HTTPS协议中的目标响应报文中的Server头会暴露目标服务器名称,X-Powered-By头会暴露目标使用的编程语言的信息,通过这些信息可以有针对的利用漏洞进行尝试。
2.2.3.2.方法
获取HTTP响应报文的方法有:
1.利用工具。如浏览器开发者工具、BurpSuite、Fiddler等工具获取
2.自己编写脚本文件,如Python的脚本文件,使用requests库
Python的代码如下:
import requests
r = requests.get('http://www.xxx.com')
print(r.headers) 这里来说说浏览器的开发者工具查看。
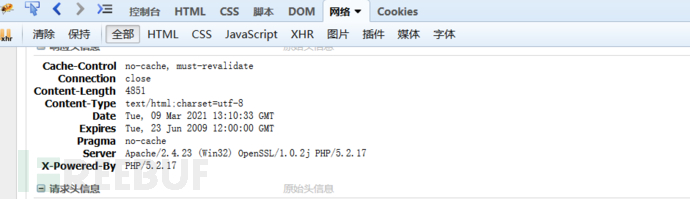
在浏览器中,按F12就能打开浏览器的开发者工具了。获取“网络”中HTTP响应报文的信息
2.3.端口信息
如果把IP地址比作一栋大楼,端口就是出入这栋大楼的门。真正的大楼只有几个门,但是一个IP地址的端口可以有65536(2的16次方)个。端口是通过端口号来标记的,端口号只有整数,范围从0到65535(2的16次方减1 )。
在端口分类中,按端口号可分为三类:
1.公认端口:范围是从0到1023(1024是2的10次方),它们绑定于一些服务,通常这些端口的通信表明了某种服务的协议。比如,21端口是FTP服务所开放的。
2.注册端口:范围是从1024到49151(49152是2的16次方减2的14次方),它们松散地绑定于一些服务。
3.动态和/或私有端口:从49152到65535(65536是2的16次方),理论上,不应为服务分配这些端口。实际上,机器通常从1024起分配动态端口。但也有例外:SUN的RPC端口从32768开始。
在计算机中,每个端口代表一个服务。
查找:
在Windows的cmd命令行中使用netstat -ano(-a:显示所有连接和侦听端口;-n:以数字形式显示地址和端口号;-o:显示拥有的与每个连接关联的进程 ID)显示开放端口。
在Linux的命令行中使用netstat -atu (-a:所有的套接字;-t :TCP连接;-u:UDP连接)显示开放端口,还可以加入-p来显示进程或程序名的相关PID。
2.3.1.端口扫描技术
通常使用专门的端口扫描工具来进行。可以详细收集目标开放的端口、服务、应用版本、操作系统、活跃主机等多种信息。
端口扫描流程:
1.存活判断:Ping,TCP扫描,UDP扫描
2.端口扫描:TCP扫描,UDP扫描
3.服务识别:基于端口,基于banner,基于指纹
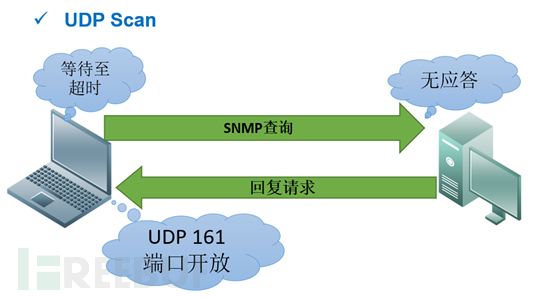
2.3.2.端口探测技术
一般通过发送建立连接过程涉及的相关报文,根据返回包的情况来判断目标端口是否开放。
主流的扫描方式:利用TCP面向连接三次握手、四次挥手过程包,UDP非面向连接请求。
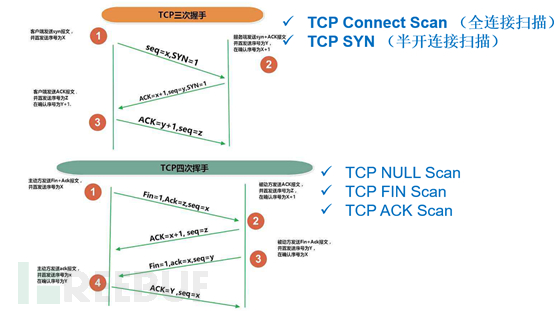
TCP Connect Scan
完成3次握手后,断开连接,被扫描服务器日志会记录下连接的内容
效率低,速度慢,准确度高
TCP SYN
发送SYN包,不建立连接。
若端口开放, 扫描器收到 SYN/ACK 标识回复
若端口关闭, 扫描器收到 RST 标识回复
效率较高,隐蔽性强
NULL扫描
发送flags标识位全为0的TCP包,用于判断操作系统类型
若扫描主机是windows系统,不管端口开放情况,都会回复RST包
若扫描主机是linux系统,若端口开放,则不回复。 若端口关闭,则回复RST包
FIN扫描
发送FIN置1的包
若端口开放, 目标主机不回复
若端口关闭, 目标主机回复RST
ACK扫描
发送ACK置1的包,获取回报TTL的值
TTL值小于64端口开启
大于64端口关闭
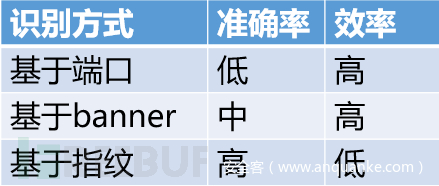
2.3.3.服务识别技术
识别端口上运行的服务,识别方式有基于端口、基于banner和基于指纹三种。
1.基于端口:根据端口默认运行的服务进行判断。
2.基于banner:根据访问端口获取的欢迎页面来判断。
3.基于指纹:根据不同系统不同服务具有不同的TCP/IP协议栈来判断。
三种识别方式在准确率和效率上各有不同,实际使用通常会相互配合使用。
banner:访问一个主机端口时,该端口所运行的服务有时会返回对应服务和版本号。
2.3.4.工具之Nmap端口扫描器的使用
2.3.4.1.介绍
Nmap(Network Mapper),在网络中具有强大的信息收集能力。
Nmap具备主机探测、服务/版本检测、操作系统检测、网络路由跟踪、Nmap脚本引擎的功能,在Kali中右键鼠标选择“打开终端”输入nmap和对应参数进行使用。也可以在Windows系统中自行安装Nmap,其中可以使用cmd的形式运行,也可以用zenmap的图形化工具来运行。
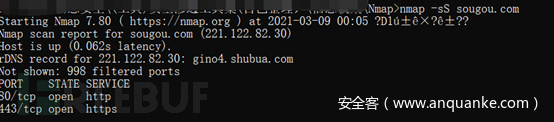
2.3.4.2.基本命令格式
nmap [参数] IP/IP段/主机名
如下图
2.3.4.3.具体参数
1.目标端口选项
-p:扫描指定的端口
-F:快速扫描100个常用的端口
-r:顺序扫描,按从小到大的顺序进行端口扫描
2.其他常用选项
-sV:检测服务端软件版本信息
-O:检测操作系统信息
-Pn:禁用nmap的主机检测功能
-A:探测服务版本、对操作系统进行识别、进行脚本扫描、进行路由探测
3.一些常用选项
TCP扫描端口选项:
-sT:使用TCP连接扫描,对目标主机所有端口进行完整的三次握手,如果成功建立连接则端口是开放的(不需要root权限,TCP扫描的默认模式,端口状态和SYN相同,耗时长)
-sS:使用半开连接(SYN stealth)扫描,使用SYN标记位的数据包进行端口探测,收到SYN/ACK包则 端口是开放的,收到RST/ACK包则端口是关闭的。(匿名扫描,默认不加类型,需要root权限,扫描速度快)
-sA:TCP ACK扫描使用ACK标志位数据包,若目标主机回复RST数据包,则目标端口没有被过滤(用于发现防 火墙的过滤规则)。
UDP扫描端口选项:
-sU:使用UDP数据包经行扫描,返回UDP报文,则端口是开放的;返回不可达则端口处于关闭或过滤状态。(DNS,SNMP和DHCP等服务,更慢更困难)
4.不常用选项
TCP扫描端口选项:
-sN:TCP NULL扫描不设置标志位,标志头是0,返回RST数据包则端口是关闭的,否则端口是打开|过滤状态
-sF:TCP FIN扫描只设置FIN标志位。若返回RST数据包则端口是关闭的,否则端口是打开|过滤状态。
-sX:TCP XMAS扫描设置FIN、PSH、URG标志位,若返回RST数据包则端口是关闭的,否则端口是打 开|过滤状态。
-sM:TCP Maimon扫描使用FIN/ACK标识的数据包,端口开放就丢弃数据包,端口关闭则回复RST(BSD)。
-sW:TCP窗口扫描,检测目标返回的RST数据包的TCP窗口字段,字段值是正值说明端口是开放状态,字段值为0,则端口关闭。
-sI:TCP Idle扫描,使用这种技术,将通过僵尸主机发送数据包与目标主机通信。
5.输出选项(很少用)
-oN:标准输出为指定的文件
-oX:生成XML格式文件,可以转换成HTML文件
6.脚本扫描
--script=--script=vuln:检查是否存在常见漏洞
--script=brute:提供暴力破解的方式 可对数据库,smb,snmp等进行简单密码的暴力猜解
--script=default:默认脚本扫描,主要搜集各种应用服务的信息,收集后,可再针对具体服务进行攻击
--script=external:利用第三方的数据库或资源
2.4.网站信息
2.4.1.敏感目录与文件
2.4.1.1.介绍
如果网站的后台被攻击者找到,那么就可以进行暴力破解,如果是设置的弱口令那就能够登录后台了;如果备份泄露,被攻击者下载下来,那么攻击者就可以代码审计,来找到网站的漏洞。而像这些后台,备份该如何找呢?这里就推荐一些工具。
2.4.1.2.工具推荐
1.dirsearch
dirsearch是一个基于python的命令行工具,旨在暴力扫描网站的页面结构,包括网页中的目录和文件。
使用:

结果:

2.御剑后台扫描工具
御剑后台扫描可以用于扫描后台,用法简单。添加需要扫描后台的域名,然后会根据你设置的字典,然后设置合适的线程和扫描速度等就可以开始扫描了。扫描结果会显示出来,点击访问即可。
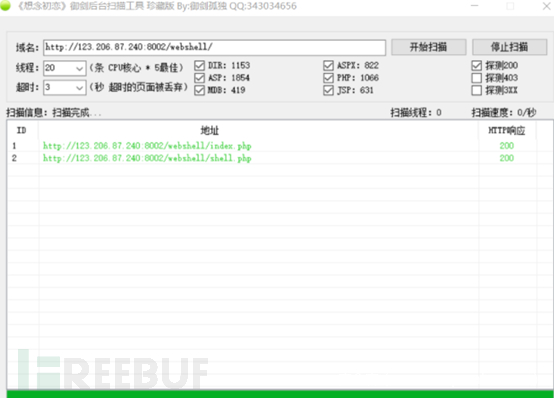
3.总结:这两个工具都是根据你所设置的字典来扫描的,所以一定要完善好自己的字典,这决定了你是否能找到别人找不到的东西。
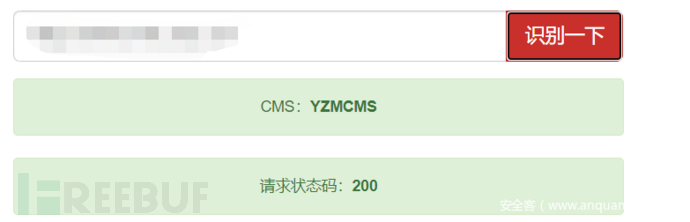
2.4.2.CMS指纹识别
2.4.2.1.介绍
CMS是"Content Management System"的缩写,意为"内容管理系统",用于网站内容管理。用户只需要下载对应的CMS软件包,就能部署搭建,并直接利用CMS。但是各种CMS都具有其独特的结构命名规则和特定的文件内容,因此可以利用这些内容来获取CMS站点的具体软件CMS与版本。
在渗透测试中,对目标服务器进行指纹识别是相当有必要的,因为只有识别出相应的Web容器或者CMS,才能查找与其相关的漏洞,然后才能进行相应的渗透操作。
2.4.2.2.查询工具

2.4.3.征信查询
2.4.3.1.企业征信
企业征信机构记录了一家企业的基本信息,历史沿革,股东及出资等信息的平台。
2.4.3.2.查询工具


2.4.4.备案号查询
2.4.4.1.介绍
备案号:
根据IP地址查询同一IP地址的其他信息。
备案号是网站是否合法注册经营的标志,一个网站域名要上线必然要经过备案程序,通过备案号反查可查询目标的所有合法网站。
2.4.4.2.查询工具